I have a list of dfs. I want to know whether there is a smart way to tell whether each df in lst has unique ID, and create a summary table like below"
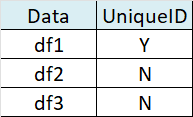
Sample data:
lst<-list(structure(list(ID = c("Tom", "Jerry", "Mary"), Score = c(85,
85, 96)), row.names = c(NA, -3L), class = c("tbl_df", "tbl",
"data.frame")), structure(list(ID = c("Tom", "Jerry", "Mary",
"Jerry"), Score = c(75, 65, 88, 98)), row.names = c(NA, -4L), class = c("tbl_df",
"tbl", "data.frame")), structure(list(ID = c("Tom", "Jerry",
"Tom"), Score = c(97, 65, 96)), row.names = c(NA, -3L), class = c("tbl_df",
"tbl", "data.frame")))
CodePudding user response:
We could loop over the list and check with n_distinct
library(dplyr)
library(stringr)
library(purrr)
map_dfr(setNames(lst, str_c("df", seq_along(lst))),
~.x %>%
summarise(UniqueID = c("N", "Y")[1 (n_distinct(ID) == n())]), .id= 'Data')
-output
# A tibble: 3 × 2
Data UniqueID
<chr> <chr>
1 df1 Y
2 df2 N
3 df3 N
CodePudding user response:
In base R:
data.frame(Data = paste0("df", seq(lst)),
UniqueID = ifelse(sapply(lst, \(x) length(unique(x$ID)) == nrow(x)), "Y", "N"))
Data UniqueID
1 df1 Y
2 df2 N
3 df3 N