For a dummy dataset df,
df <- structure(list(date = c("2021-07-31", "2021-08-31", "2021-09-30",
"2021-10-31", "2021-11-30", "2021-12-31", "2022-01-31", "2022-02-28",
"2022-03-31", "2022-04-30", "2022-05-31"), PMI = c(52.4, 48.9,
51.7, 50.8, 52.2, 52.2, 51, 51.2, 48.8, 62.7, 48.4), Exchange_rate = c(5.1,
5.1, 4.9, 4.9, 5, 5.1, 5.3, 5.5, 5.8, 6.1, 5.9), BCI = c(54.6,
50, 54.5, 51.6, 49.2, 45.1, 52.6, 53.8, 51.3, 40.8, 37.3)), class = "data.frame", row.names = c(NA,
-11L))
Out:
date PMI Exchange_rate BCI
1 2021-07-31 52.4 5.1 54.6
2 2021-08-31 48.9 5.1 50.0
3 2021-09-30 51.7 4.9 54.5
4 2021-10-31 50.8 4.9 51.6
5 2021-11-30 52.2 5.0 49.2
6 2021-12-31 52.2 5.1 45.1
7 2022-01-31 51.0 5.3 52.6
8 2022-02-28 51.2 5.5 53.8
9 2022-03-31 48.8 5.8 51.3
10 2022-04-30 62.7 6.1 40.8
11 2022-05-31 48.4 5.9 37.3
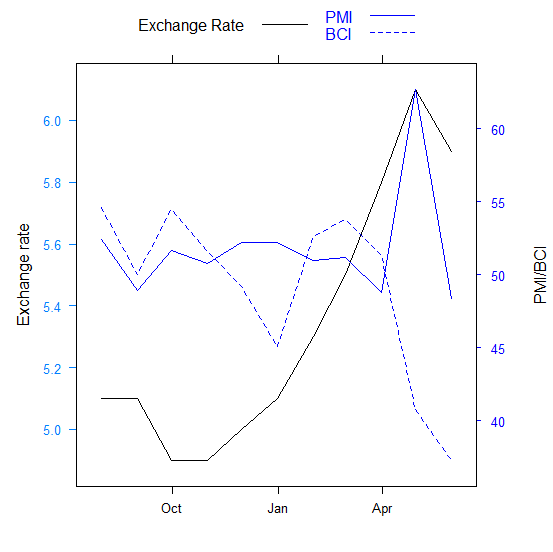
I'm trying to plot a time series plot with dual y axis, I set Exchange_rate to the left axis and PMI and BCI to the right axis. To achieve this, I need to get the max and min of Exchange_rate, the max and min of all values of PMI and BCI. At the same time, subtract and add an appropriate value to these minimum and maximum values, respectively, so that all values are included in the final plot.
Using print(skimr::skim(df)), I print out:
-- Variable type: numeric -----------------------------------------------------------------------------------------------
skim_variable n_missing complete_rate mean sd p0 p25 p50 p75 p100 hist
1 PMI 0 1 51.8 3.88 48.4 49.8 51.2 52.2 62.7 ▇▅▁▁▁
2 Exchange_rate 0 1 5.34 0.425 4.9 5.05 5.1 5.65 6.1 ▇▁▁▁▂
3 BCI 0 1 49.2 5.74 37.3 47.2 51.3 53.2 54.6 ▁▁▁▂▇
As you can see, p0 and p100 in the result are the minimum and maximum values of each column, respectively. For the left axis, I need to get approximately c(4.5, 6.5) as the upper and lower limits of the value, and for the right axis, I need to get approximately c(37, 63) as the upper and lower limits of the value,
My expected results are as follows (not need to be exactly the same as the maximum and minimum values below):
left_y_axis_limit <- c(4.5, 6.5)
right_y_axis_limit <- c(37, 63)
Suppose we will have other data with a new range of values, given the column names that will be displayed on the left and right axes, how could we deal with this problem in an adaptive way? Thanks.
CodePudding user response:
1) You don't actually need that calculation if all you need is dual axes. The question did not specify the plot so we will assume classic graphics. Convert df to a zoo object and then use plot.zoo first plotting the Exchange_rate and then overlaying that with a PMI/BCI plot. There is a further example in the Examples section of ?plot.zoo . You may need to adjust the 0.15 according to how far you like the second y axis label away from the axis.
(continued after graphics)
library(zoo)
z <- read.zoo(df)
opar <- par(mai = c(.8, .8, .2, .8))
with(z, plot(Exchange_rate, type = "l", xlab = ""))
par(new = TRUE)
plot(z[, c("PMI", "BCI")], screens = 1, ann = FALSE, yaxt = "n", col = "blue",
lty = 1:2)
axis(side = 4, col = "blue")
usr <- par("usr")
text(usr[2] .15 * diff(usr[1:2]), mean(usr[3:4]), "PMI/BCI",
srt = -90, xpd = TRUE, col = "blue")
legend(x = "topleft", bty = "n", lty = c(1, 1:2), col = c("black", "blue", "blue"),
legend = c("Exchange Rate", "PMI", "BCI"))
par(opar)
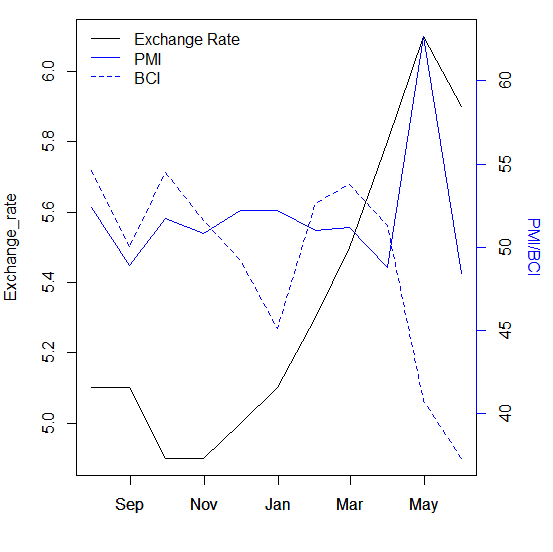
2) With ggplot2 one can use sec.axis= but it requires that you calculate your own transformation whereas in classic graphics one can use par("usr") to get the key data. How to do it with ggplot2 is described in