I'm using R version 4.2.1 and I have a working solution for what I want to achieve (see below). Yet, it is extremely inefficient and would run for ~4 days to generate only one variable. Hence, I'm looking for a more efficient way to achieve my desired outcome.
Data and problem description
I have roughly 500,000 observations of 700ish firms across several time periods in a data.table. My data are uniquely identified by firm_id, period, and destination. I'm interested in whether and when these firms start operating at a specific destination. I know in which period a firm is operating at which destination. This information is provided by combining destination with another already existing variable called destination_presence. destination_presence is stored as numericand provides information on whether a firm is operating at the destination stated by destination. destination_presence can be NA, 1(= firm operates at the respective destination), or 0(= firm does not operate at the respective destination). destination is a factor with 66 levels (e.g., "usa", "canada", ...) which is why for every firm_id-period-combination there are 66 observations in the data set.
My new variable internationalization can be NA, 1(= firm started operations at respective destination in the current period), 0(= firm did not start operation at respective destination in current period). Hence, internationalization == 1 only happens at that time when a firm starts operations at a specific destination. Note, that this could occur more than one time as, e.g., a firm could start operations at destination D in period 2, leave destination D in period 4, and enter destination D again in period 9.
Here is a shortened example of the data:
Data example
#load packages
library(data.table)
dt <- as.data.table(
structure(list(
firm_id = structure(as.factor(c(rep("f1", 18), rep("f2", 18), rep("f3", 18), rep("f4", 18)))),
period = structure(as.factor(c(rep("3", 6), rep("5", 6), rep("6", 6), rep("1", 6), rep("2", 6), rep("3", 6), rep("0", 6), rep("1", 6), rep("2", 6), rep("7", 6), rep("8", 6), rep("9", 6)))),
min_period = structure(c(rep(3, 18), rep(1, 18), rep(0, 18), rep(7, 18))),
destination = structure(as.factor(c("usa", "chile", "austria", "kenya", "china", "new zealand", "usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand"))),
destination_presence = structure(c(rep(NA, 6), 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, rep(NA, 6), 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1,0, 0, 1, 1, 1, 1, rep(NA, 6)), class = "numeric")),
.Names = c("firm_id", "period", "min_period", "destination", "destination_presence" ), row.names = c(NA, 5), class = "data.table"))
Current approach
# load packages
library(data.table)
# order data by firm_id, period, and destination to make sure that all data are similarly ordered
dt <-
dt[with(dt, order(firm_id, period, destination)), ]
# Step 1: fill first variable for minimum periods as in these cases there is no prior period with which to compare
dt[, internationalization := ifelse(
period == min_period & # min_period is the minimum period for a specific firm
destination_presence == 1,
1,
NA
)]
# show internationalization variable output
summary(as.factor(dt$internationalization))
# Step 2:
# there are 6 rows for every firm_id-period combination because there are 6 different levels in the factor variable destination (i.e., 6 different countries) in the example data set
# hence, for the first 6 rows there are no prior ones to compare with. therefore, start in row 7
for (i in 7:nrow(dt)) {
print(i) # print i to know about progress of loop
dt$internationalization[i] <-
# a) if there is already a value in internationalization, keep this value (output from Step 1)
ifelse(
!is.na(dt$internationalization[i]),
dt$internationalization[i],
# b) if there is no information on the international operation destinations of a firm in the current period, insert NA in internationalization
ifelse(
is.na(dt$destination_presence[i]),
NA,
# c) if in prior period (i-6 because of 6 country levels per firm_id-period entry) there are no information on destination presence, treat observations as first internationalization
ifelse(
is.na(dt$destination_presence[i - 6]) & dt$firm_id[i] == dt$firm_id[i - 6],
dt$destination_presence[i],
# c) if in last period (i - 6) a specific firm was not operating at a specific destination (dt$destination_presence[i - 6] != 1) and is operating at this specific destination in the current period (dt$destination_presence[i] == 1), set internationalization == 1
ifelse(
(dt$destination_presence[i] == 1) & (dt$destination_presence[i - 6] != 1) & (dt$firm_id[i] == dt$firm_id[i - 6]),
1,
0
)
)
)
)
}
Desired outcome
This should match outcome from the approach described above.
# desired outcome
desired_dt <- as.data.table(
structure(list(
firm_id = structure(as.factor(c(rep("f1", 18), rep("f2", 18), rep("f3", 18), rep("f4", 18)))),
period = structure(as.factor(c(rep("3", 6), rep("5", 6), rep("6", 6), rep("1", 6), rep("2", 6), rep("3", 6), rep("0", 6), rep("1", 6), rep("2", 6), rep("7", 6), rep("8", 6), rep("9", 6)))),
min_period = structure(c(rep(3, 18), rep(1, 18), rep(0, 18), rep(7, 18))),
destination = structure(as.factor(c("usa", "chile", "austria", "kenya", "china", "new zealand", "usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand","usa", "chile", "austria", "kenya", "china", "new zealand"))),
destination_presence = structure(c(rep(NA, 6), 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, rep(NA, 6), 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1,0, 0, 1, 1, 1, 1, rep(NA, 6)), class = "numeric"),
internationalization = structure(c(rep(NA, 6), 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, rep(NA, 6), rep(0, 5), 1, rep(0,6), 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, rep(NA, 6)))),
.Names = c("firm_id", "period", "min_period", "destination", "destination_presence", "internationalization"), row.names = c(NA, 6), class = "data.table"))
Looking forward to your suggestions on how to make the code more efficient!
CodePudding user response:
This can be done with a single chained command using data.table's setorder and shift functions. It will be very fast.
setorder(dt, firm_id, destination, period)[, internationalization := destination_presence*(firm_id != shift(firm_id, 1, "") | destination != shift(destination, 1, "") | !pmax(0, shift(destination_presence), na.rm = TRUE))]
Notice that min_period is not used.
CodePudding user response:
Edited to include @jblood94 code in the performaces below
The for loop is the culprit for slowing your code here. An tidyverse alternative option would help speed the process.
Code
dt= as.data.frame(dt) #transform your data into a data frame
dt$id = 1:nrow(dt) # Add a unique row id to select them later
dt$period = as.numeric(dt$period) # Change the factor into numeric
#Create an intermediate dataframe only with the data of interest
temp = dt %>% filter(destination_presence == 1) %>%
group_by(firm_id, destination) %>%
mutate(b = ifelse(lag(period)==period-1, 0, 1), #if period are consecutive transform to 0
int = ifelse(is.na(b)|b==1, 1, 0))%>% #the final internationalization variable to be added in the original data frame
select(-b) #remove the useless column
dt$inter = dt$destination_presence # Create the internationalization column based on the destination
dt[temp$id, "inter"] = temp$int # Transfer the column for the identified rows above
dt
firm_id period min_period destination destination_presence internationalization
1: f1 3 3 austria NA NA
2: f1 5 3 austria 0 0
3: f1 6 3 austria 0 0
4: f1 3 3 chile NA NA
5: f1 5 3 chile 0 0
6: f1 6 3 chile 0 0
7: f1 3 3 china NA NA
8: f1 5 3 china 0 0
9: f1 6 3 china 0 0
10: f1 3 3 kenya NA NA
11: f1 5 3 kenya 1 1
12: f1 6 3 kenya 1 0
13: f1 3 3 new zealand NA NA
14: f1 5 3 new zealand 1 1
15: f1 6 3 new zealand 1 0
16: f1 3 3 usa NA NA
17: f1 5 3 usa 0 0
Performance
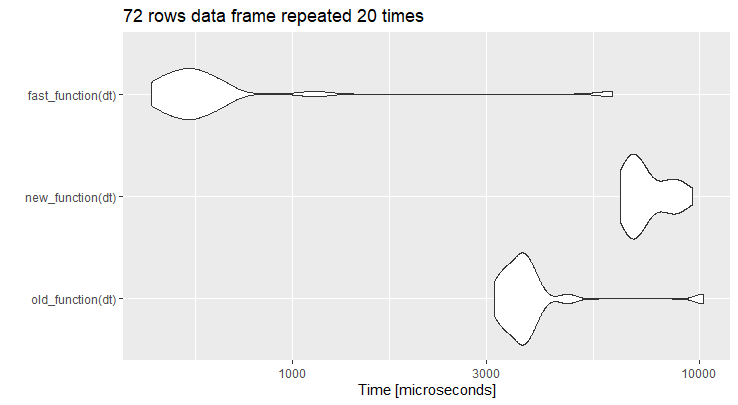
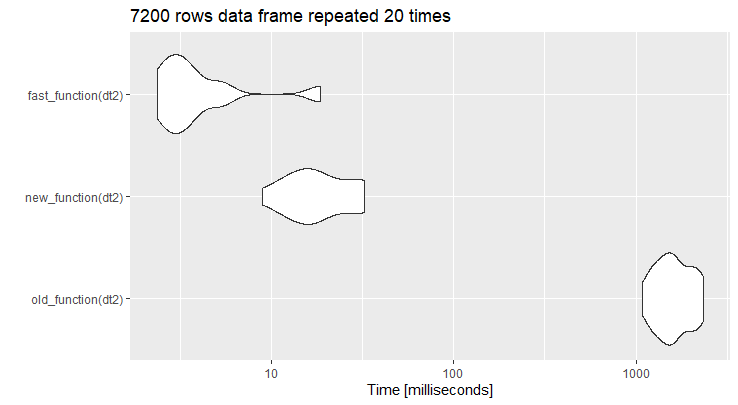
Edited: Code from @jblood94 added as fast_function
I warped up your code as old_function and the code abode as new_function. Your code is actually faster to run on the example data frame you provided. However when the number of row is increase the new_function is far much effective.