I am trying my hand at webscraping using BeautifulSoup.
I had posted this before here, but I was not very clear as to what I wanted, so it only partially answers my issue.
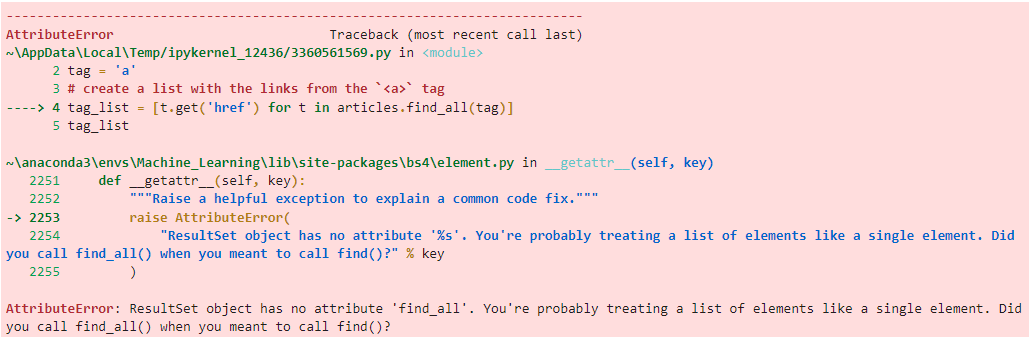
CodePudding user response:
That is cause articles is a ResultSet of soup.find_all(article_tag) what you can check with type(articles)
To get your goal you have to iterate articles first - So simply add an additional for-loop to your list comprehension:
[t.get('href') for article in articles for t in article.find_all(tag)]
In addition you may should use a set comprehension to avoid duplicates and also concat paths with base url:
list(set(t.get('href') if t.get('href').startswith('http') else 'https://bigbangtheory.fandom.com' t.get('href') for article in articles for t in article.find_all(tag)))
Output:
['https://bigbangtheory.fandom.com/wiki/The_Killer_Robot_Instability',
'https://bigbangtheory.fandom.com/wiki/Rajesh_Koothrappali',
'https://bigbangtheory.fandom.com/wiki/Bernadette_Rostenkowski-Wolowitz',
'https://bigbangtheory.fandom.com/wiki/The_Valentino_Submergence',
'https://bigbangtheory.fandom.com/wiki/The_Beta_Test_Initiation',
'https://bigbangtheory.fandom.com/wiki/Season_2',
'https://bigbangtheory.fandom.com/wiki/Dr._Pemberton',...]