This is an example of input string:
import re
input_text = "Hello, I will dictate the following numbers in Spanish, write them down ochocientos veinti-ocho sete cientos quince dieci siete dieci-seis,ochocientos veinti ocho"
Here are the 3 functions that perform replacements of one substring for another within the original string. The conditional statements within the code are written in pseudocode, since they are based on the same type of regex condition (some are if conditions and others if not conditions).
def hundreds_replacement(input_text, hundreds_colloquial_list_b, hundreds_numbers_list_b, hundreds_numbers_list_a2, hundreds_numbers_list_a1):
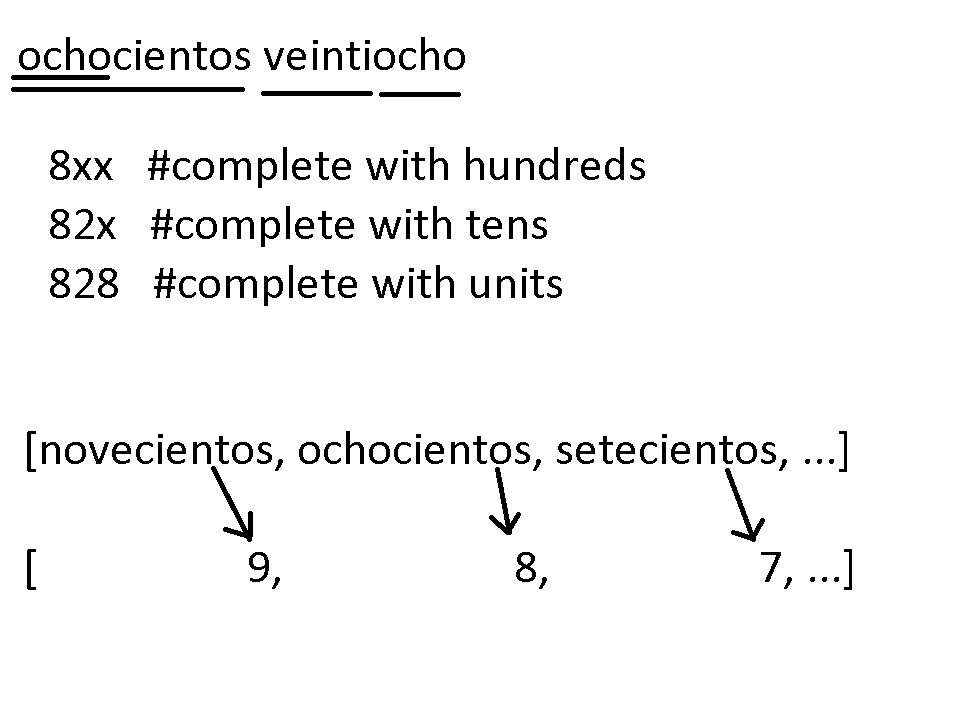
#If "ten" digit AND "unit" digit after the hundreds digit : --> {2 to 9}XX
for nro in range(len(hundreds_colloquial_list_b)):
input_text = re.sub(hundreds_colloquial_list_b[nro].replace(" ", r"[\s|-|]"), hundreds_numbers_list_b[nro], input_text)
#Tens
input_text = tens_replacement(input_text, unit_colloquial_list, unit_numbers_list)
#Units
input_text = unit_replacement(input_text, unit_colloquial_list, unit_numbers_list)
#Elif NO "ten" digit after the hundreds digit : --> {2 to 9}0X
for nro in range(len(hundreds_colloquial_list_b)):
input_text = re.sub(hundreds_colloquial_list_b[nro].replace(" ", r"[\s|-|]"), hundreds_numbers_list_a1[nro], input_text)
#Units
input_text = unit_replacement(input_text, unit_colloquial_list, unit_numbers_list)
#Elif NO "ten" digit AND NO "unit" digit after the hundreds digit : --> {2 to 9}00
for nro in range(len(hundreds_colloquial_list_b)):
input_text = re.sub(hundreds_colloquial_list_b[nro].replace(" ", r"[\s|-|]"), hundreds_numbers_list_a2[nro], input_text)
#Elif "ten" digit AND "unit" digit after the hundreds digit : --> 1XX
for nro in range(len(r"ciento[\s|-|]")):
input_text = re.sub(r"ciento[\s|-|]", "1", input_text)
#Tens
input_text = tens_replacement(input_text, unit_colloquial_list, unit_numbers_list)
#Units
input_text = unit_replacement(input_text, unit_colloquial_list, unit_numbers_list)
#Elif NO "ten" digit after the hundreds digit : --> 10X
for nro in range(len(hundreds_colloquial_list_b)):
input_text = re.sub(hundreds_colloquial_list_b[nro].replace(" ", r"[\s|-|]"), hundreds_numbers_list_a1[nro], input_text)
#Units
input_text = unit_replacement(input_text, unit_colloquial_list, unit_numbers_list)
#Elif NO "ten" digit AND NO "unit" digit after the hundreds digit : --> 100
for nro in range(len(r"cien")):
input_text = re.sub(r"cien", "100", input_text)
return input_text
def tens_replacement(input_text, tens_colloquial_list_b, tens_numbers_list_b, tens_colloquial_list_a, tens_numbers_list_a):
for nro in range(len(tens_colloquial_list_b)):
input_text = re.sub(tens_colloquial_list_b[nro].replace(" ", r"[\s|-|]"), tens_numbers_list_b[nro], input_text)
#If (replacement):
input_text = unit_replacement(input_text)
#If NOT (replacement):
for nro in range(len(tens_colloquial_list_a)):
input_text = re.sub(tens_colloquial_list_a[nro].replace(" ", r"[\s|-|]"), tens_numbers_list_a[nro], input_text)
return input_text
def unit_replacement(input_text, unit_colloquial_list, unit_numbers_list):
#Units: Symbols of the 10 digits of the decimal system
for nro in range(len(unit_colloquial_list)):
input_text = re.sub(unit_colloquial_list[nro], unit_numbers_list[nro], input_text)
return input_text
Here are the lists with the replacements that each function must perform in each case
hundreds_colloquial_list = ["novescientos", "nove cientos", "ochoscientos", "ocho cientos", "setescientos", "sete cientos", "seis cientos", "quinientos", "cuatros cientos", "cuatro cientos", "trecientos", "tres cientos", "docientos", "dos cientos", "novescientas", "nove cientas", "ochoscientas", "ocho cientas", "setescientas", "sete cientas", "seis cientas", "quinientas", "cuatros cientas", "cuatro cientas", "trecientas", "tres cientas", "docientas", "dos cientas"]
hundreds_numbers_list_a2 = ["900", "900", "800", "800", "700", "700", "600", "500", "400", "400", "300", "300", "200", "200", "900", "900", "800", "800", "700", "700", "600", "500", "400", "400", "300", "300", "200", "200"]
hundreds_numbers_list_a1 = ["90" , "90" , "80" , "80" , "70" , "70" , "60" , "50" , "40" , "40" , "30" , "30" , "20" , "20" , "90" , "90" , "80" , "80" , "70" , "70" , "60" , "50" , "40" , "40" , "30" , "30" , "20" , "20" ]
hundreds_numbers_list_b = ["9" , "9" , "8" , "8" , "7" , "7" , "6" , "5" , "4" , "4" , "3" , "3" , "2" , "2" , "9" , "9" , "8" , "8" , "7" , "7" , "6" , "5" , "4" , "4" , "3" , "3" , "2" , "2" ]
tens_colloquial_list_a = ["noventa", "ochenta", "setenta", "sesenta", "cincuenta", "cuarenta", "treinta", "veinte", "dieci nueve", "dieci ocho", "dieci siete", "dieci seis", "quince", "catorse", "trece", "doce", "once", "diez"]
tens_numbers_list_a = ["90", "80", "70", "60", "50", "40", "30", "20", "19", "18", "17", "16", "15", "14", "13", "12", "11", "10"]
tens_colloquial_list_b = ["noventa y", "ochenta y", "setenta y", "sesenta y", "cincuenta y", "cuarenta y", "treinta y", "veinti "]
tens_numbers_list_b = ["9", "8", "7", "6", "5", "4", "3", "2"]
unit_colloquial_list = ["nueve", "ocho", "siete", "seis", "cinco", "cuatro", "tres", "dos", "una", "uno", "un", "cero"]
unit_numbers_list = ["9", "8", "7", "6", "5", "4", "3", "2", "1", "1", "1", "0"]
Finally here will be the calls to the 3 functions in charge of the replacements with the re.sub() method
#Hundreds
input_text = hundreds_replacement(input_text, hundreds_colloquial_list, hundreds_numbers_list_b, hundreds_numbers_list_a2, hundreds_numbers_list_a1)
#Tens
input_text = tens_replacement(input_text, tens_colloquial_list_b, tens_numbers_list_b, tens_colloquial_list_a, tens_numbers_list_a)
#Units
#If there are no matches of patterns associated with tens or/and of patterns associated with hundreds before
input_text = unit_replacement(input_text, unit_colloquial_list, unit_numbers_list)
print(repr(input_text)) #print output
Sorry for the length of the code, but this is the most I could reduce the logic (since the original code includes conversions for thousands and millions) of the code to place it in the stack question. Even so, I made sure that there is the input_text, the 3 functions in charge of the replacement of the numerical figures (which are long because they have several nested if statements), and the lists with the equivalences in Spanish of the name of a number with its symbol.
Note that the indices of the for loops cause the lists to be traversed at the same time, so that the name of the number and its symbol remain within the same iteration of the loop.
And the correct output for this example is:
"Hello, I will dictate the following numbers in Spanish, write them down 828 715 17 16,828"
CodePudding user response:
This is quite a complicated question and it's hard for me to answer fully because the code provided is confusing.
However, at a high level, you appear to have two concerns:
- How can I make the program do one thing if
re.subwould have done something, and another thing otherwise? - How do I correctly convert colloquial numbers to digits?
The first is quite simple: There are other methods that merely test the match, such as re.search:
if re.search(your_regex_pattern, input_text):
do_something()
# note that we haven't subbed at this point, so you may want to call re.sub here as well
else:
do_another_thing()
Another way is to compare the string before and after:
output_text = re.sub(your_regex_pattern, replacement, input_text)
if input_text != output_text:
do_something()
else:
do_another_thing()
This second way is simpler, so in my opinion better, but there's a false negative if the replacement generates an identical string. Sounds like this will not be a problem for you.
For the second, here's a better way (I don't speak Spanish, so I will use English words):
- Figure out a way to separate number phrases, e.g.
two hundred twenty, two->["two hundred twenty", "two"] - Split each phrase into its component words with
str.split,str.trim, etc. E.g.["two hundred twenty", "two"]->comps = [["two", "hundred", "twenty"], ["two"]] - Define a dictionary of every colloquial name mapping to a numeral. This will be much more readable and concise than your lists and regexes. E.g.
names = {"two": 2, "hundred": 100, "twenty": 20} - Map the dictionary over your components (if you get
KeyError, go back and add the missing name to your dict). E.g.numerals = [[names[w] for w in u] for u in comps] - Now simply sum every sub list:
numbers = [sum(u) for u in numerals]
You might notice that the first bullet is not always possible. For example, if I say "two hundred twenty two" am I trying to say "222", or "200, 22" or "220, 2" or "200, 20, 2"? There's no way to know without additional information. The additional information in my example is the comma. If you don't have this additional information in your input, your job will be very hard (it becomes a combinatorial/graph theory/backtracking problem).
I don't know how Spanish numbers work, but for example in French they do some really weird stuff like saying "four twenty ten" (quatre vingt dix) instead of "ninety" (nonante in Belgium). If Spanish also has that, it will make the previous issue even worse.