We have a PySpark dataframe that represents a school with 35 students and 3 classes, with each Row representing a student. Class #1 has 20 students, Class #2 has 10 students and Class #3 has 5 students.
We want to compare the three classes and thus we will assign an exam to a minimum of 4 students and a maximum of half the size of the class in each class. These students must be selected randomly.
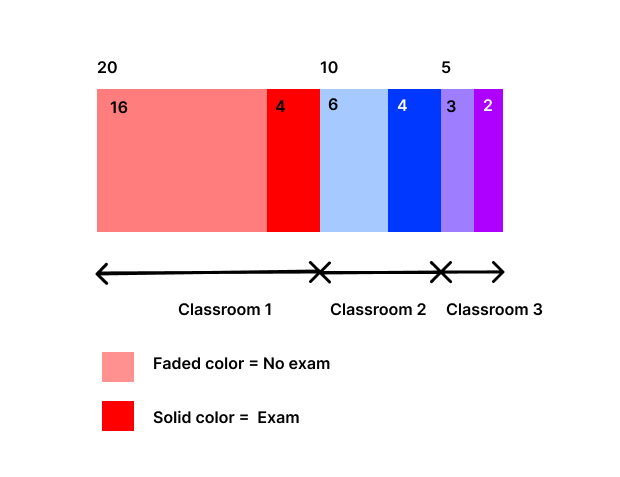
How can this task be executed as efficiently as possible? I share here the code that I have built so far.
students = students.withColumn("exam", sf.lit(None))
for class_ in students.select("classroom").distinct().collect():
for group_ in ['TEST', 'NO_TEST']:
subdf = students.filter(sf.col("classroom") == class_[0])
if group_ == 'TEST':
subdf_group = subdf.sample(False, 0.5).limit(4) \
.withColumn("exam", sf.lit("EXAM"))
else:
subdf_group = subdf.filter(sf.isnull(sf.col("exam"))) \
.withColumn("exam", sf.lit("NO_EXAM"))
students = self.update_df(students, subdf_group)
def update_df(self, df_, new_df_):
"""
A left join that updates the values from the students df with the new
values on exam column.
"""
out_df = df_.alias('l') \
.join(new_df_.select("student_id", "exam").alias('r'),
on="student_id", how="left").select(
"student_id",
self.update_column("exam")
)
return out_df
def update_column(column_name: str, left: str ='l', right: str ='r'):
"""
When joining two dfs with same column names, we keep the column values from
the right dataframe when values on right are not null, else, we keep the
values on the left column.
"""
return sf.when(~sf.isnull(sf.col(f'{right}.{column_name}')),
sf.col(f'{right}.{column_name}')) \
.otherwise(sf.col(f'{left}.{column_name}')).alias(column_name)
This is a toy example. In reality we have 135 classes and a total of 4 million rows in the dataframe, and the task is running poorly with the code that I have shared above.
CodePudding user response:
The code you shared is very un-sparky in nature.
Best performance is when not using python loops and multiple shuffles. In the code shared the python loop creates a Spark plan with num of classes in the dataset X filters and joins (join = heavy shuffle operation) hence the poor performance.
Assuming you have a dataframe with two columns ["class", "student"] here is how I would do this using window functions.
Spark will send each window function partition (in our case class) to a different executor so you will parallelize the sampling with no need to filter the big df each time.
from pyspark.sql.functions import col, row_number, rand, count
from pyspark.sql.window import Window
df \
.select(
"*",
row_number().over(Window.partitionBy('class').orderBy(rand(123))).alias('random_position'),
count("*").over(Window.partitionBy('class')).alias('num_students_in_class'),
) \
.withColumn(
"takes_test",
(col("random_position") <= 4) &
((col("num_students_in_class") / 2) > col("random_position")))