I need to find values that exist in both files. For that reason I had to merge vertically the 2 columns I wanted, removed duplicates and saved it as a new .xlsx file.
import pandas as pd
df_initial=pd.read_excel('receptors.xlsx')
df=pd.read_excel('C:/Users/GStamataki/PycharmProjects/pythonProject/nozeros-noligands-knockout/adipose-knockout.xlsx')
df["Proteins"] = df["Protein1"] df["Protein2"] #merged the 2 columns
df_updated=df["Proteins"]
df_updated.drop_duplicates()
print(df_updated)
writer = pd.ExcelWriter('cols.xlsx')
df_updated.to_excel(writer)
writer.save()
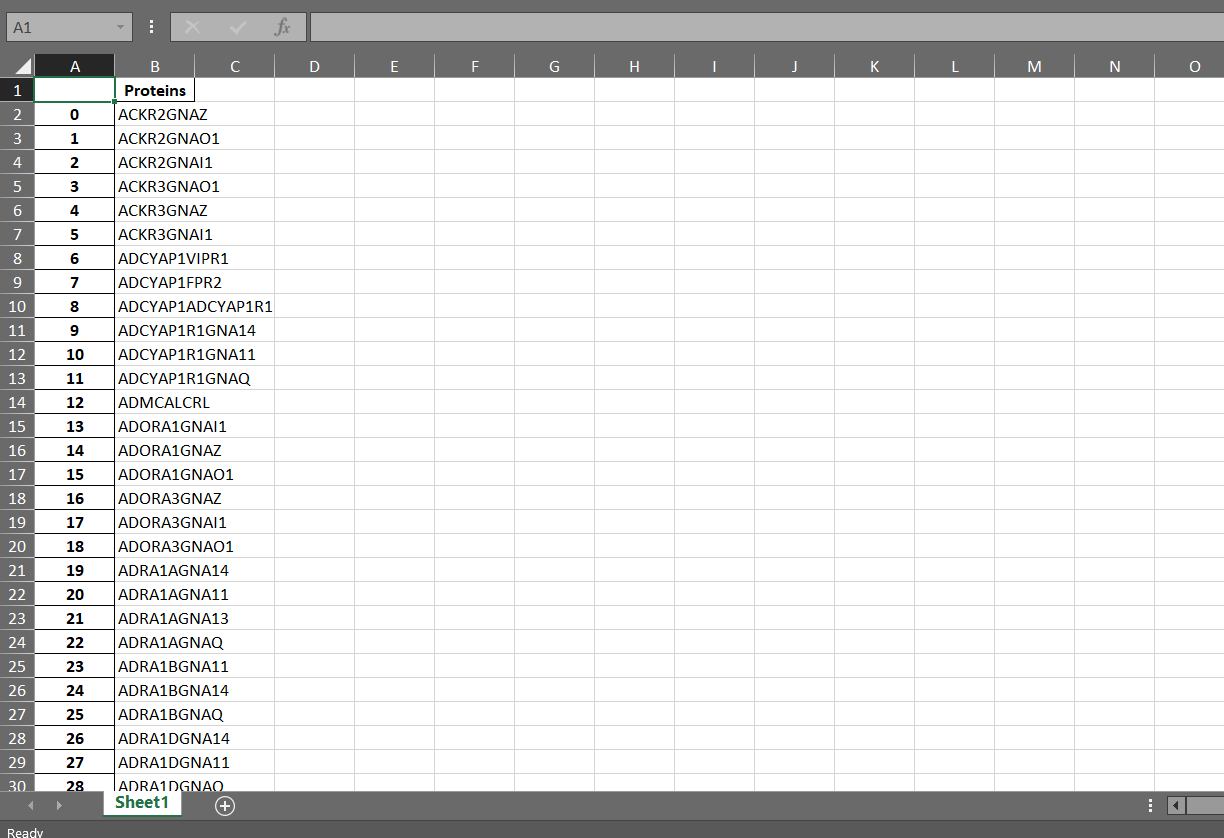
This is how the column Proteins looks like after the merge of the two columns:
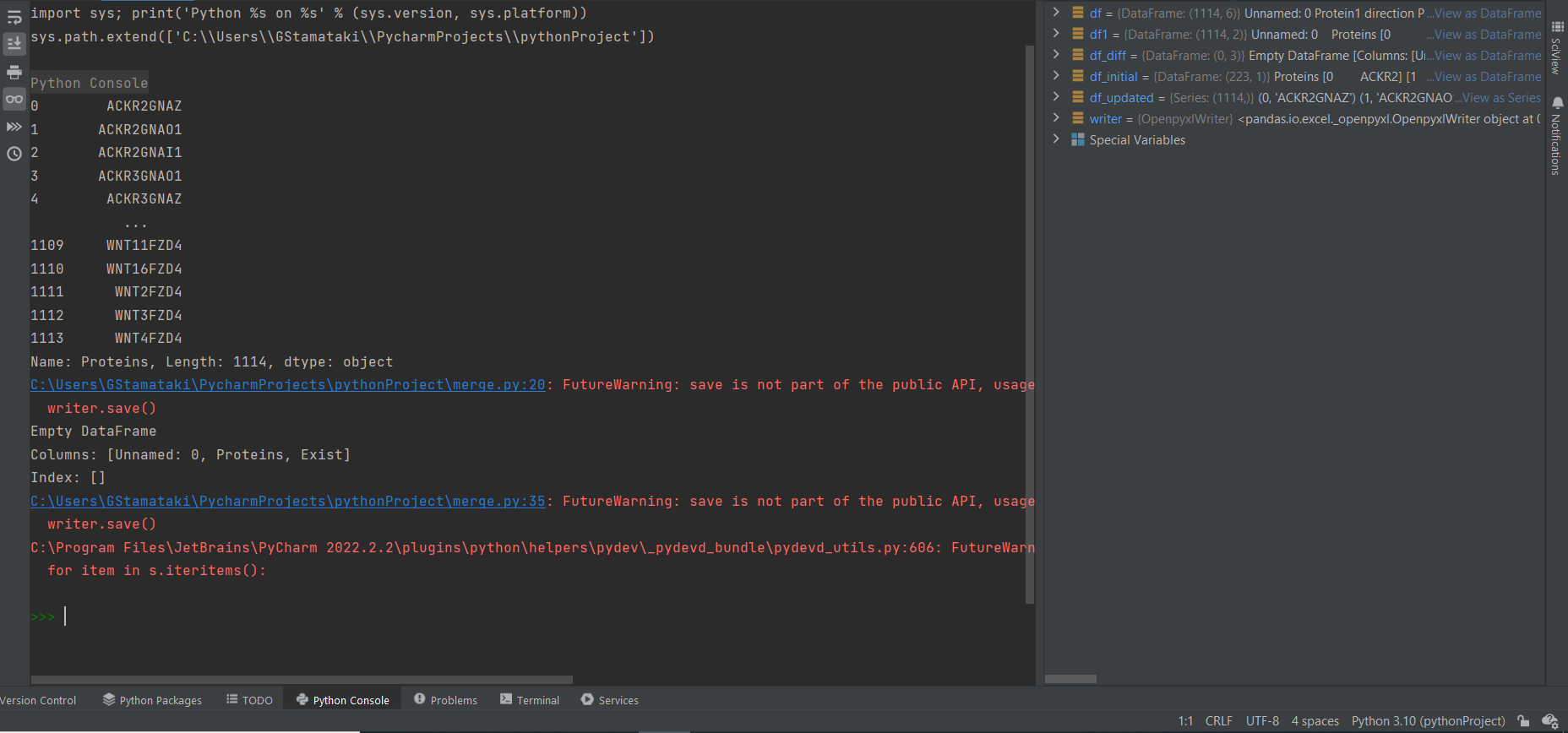
The output of this is :
Note that I tried to drop the index column that was created using df_updated = df_updated.reset_index(ignore_index= False) but it did not work.
Now, I want to compare the newly created .xlsx file with the receptors.xlsx one and print out only the values that existed in both. I am trying to do it using the inner join method, but it returns an empty dataframe.
df1= pd.read_excel('cols.xlsx')
df_diff = pd.merge(df1, df_initial, how="inner", on='Proteins', indicator="Exist")
df_diff = df_diff.query("Exist=='both'")
print(df_diff)
writer = pd.ExcelWriter('merged.xlsx')
df_diff.to_excel(writer)
writer.save()
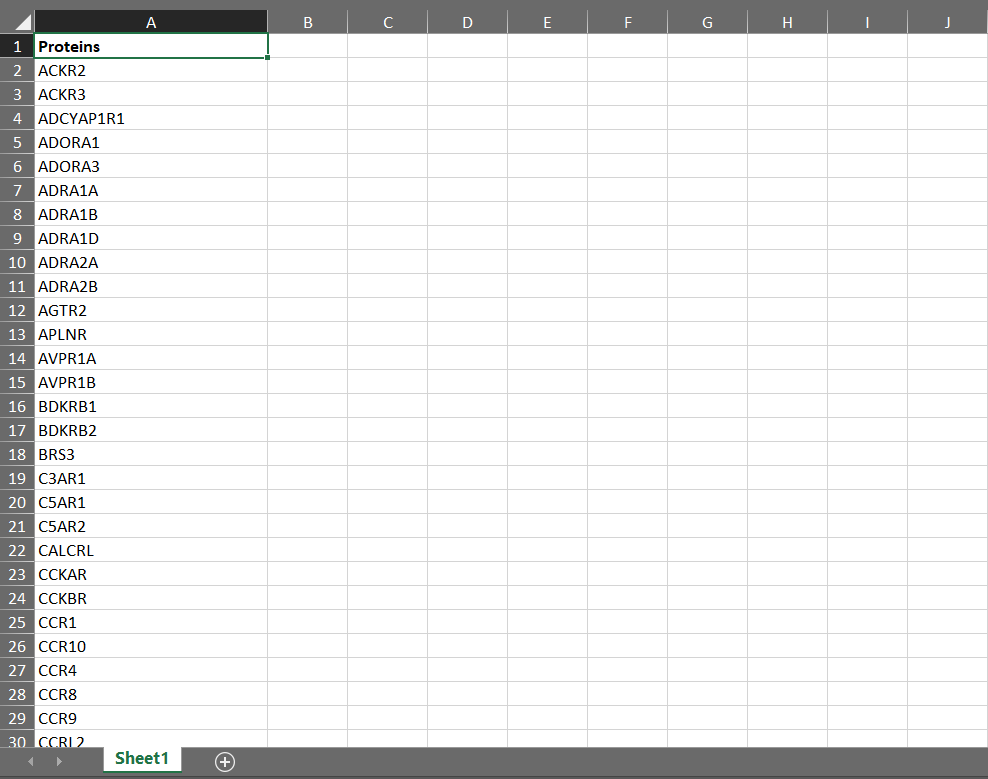
receptors.xlsx :
What am I doing wrong? I probably have made it super complicated but I couldn't think of another way.
CodePudding user response:
You're close to reach your excpected result. However, you don't need to save df_updated to an Excel file to compare it with df_initial. You can directly use pandas.merge. Also, there is no need for a query since the inner join will automatically keep the intersection of the two dataframes.
Try this :
import pandas as pd
# --- Initialiazing Receptors
df_initial = pd.read_excel('receptors.xlsx')
# --- Cleaning-up Adipose Knockout
df = pd.read_excel('C:/Users/GStamataki/PycharmProjects/pythonProject/nozeros-noligands-knockout/adipose-knockout.xlsx')
df_updated = pd.concat([df['Protein1'],df['Protein2']], ignore_index=True).drop_duplicates().to_frame(name='Proteins')
# --- Merging/Comparing Adipose & Receptors
df_diff = pd.merge(df_updated, df_initial, on="Proteins") # how="inner" by default
print(df_diff)
# --- Saving the result in a spreasheet
with pd.ExcelWriter('merged.xlsx') as writer:
df_diff.to_excel(writer, index=False)
CodePudding user response:
df1 = pd.read_excel(<first file>)
df2 = pd.read_excel(<second file>)
df_join = df1.merge(df2, on='Protein')
Combine columns as you wish before merging.