I'm looking for an explanation for the following issue. I'm fitting an XGB model to a dataset of 50k rows, 26 features.
I'm running a gridsearch with varying max_depths n_estimators and the model is performing much better with deeper trees (with a depth of 14 im getting c.87 accuracy, c.83 precision, when I reduce the depth to 5 I have a reduced performance of .85 accuracy and .81 precision). On the validation set, the performance is the same for both models (.81 accuracy, .78 precision).
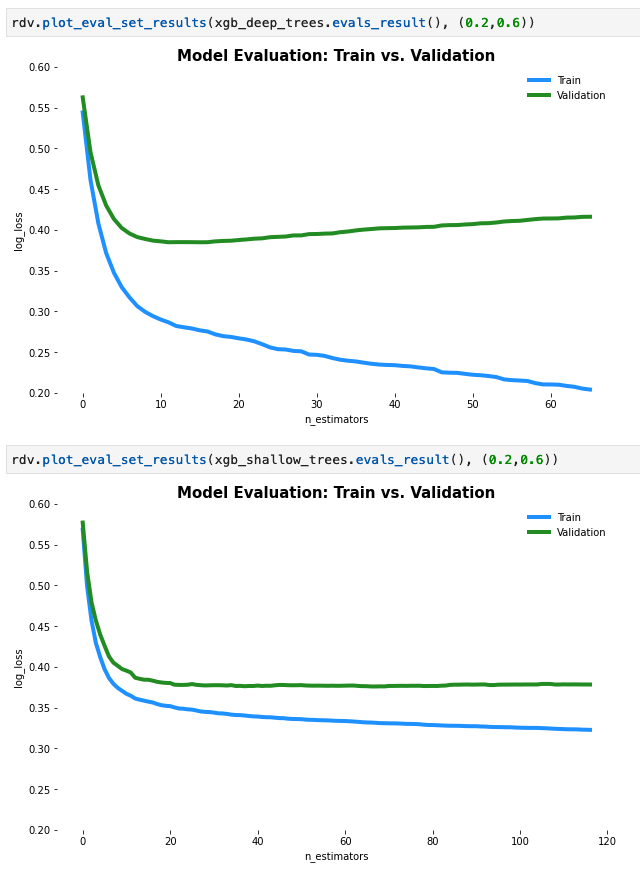
So at surface level it seems like the deeper model is performing the same or better, but when I plot learning curves for the two models, the deeper model looks like its overfitting. The image below shows the learning curves for the two models with the deeper trees at the top and the shallower trees at the bottom.
How can this be explained?
CodePudding user response:
One very simple reason may be the capacity. The first model, the deeper one, has much more capacity. Thus, due to the capacity it can learn the useful things, leading to the good performance, and after a while it will start to learn things that lead to the overfitting. This usually happens to models with big capacity.
Your second model doesn't have enough capacity to overfit, which may also lead to the fact that it does not have enough capacity to learn useful things.
You can also see on the plots that the bigger model starts to overfit around epoch 10, but it already managed to obtain a lower loss than the second model.