I have a dataframe like below where I have 2 million rows. The sample data can be found 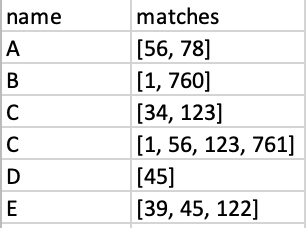
The list of matches in every row can be any number between 1 to 761. I want to count the occurrences of every number between 1 to 761 in the matches column altogether. For example, the result of the above data will be:
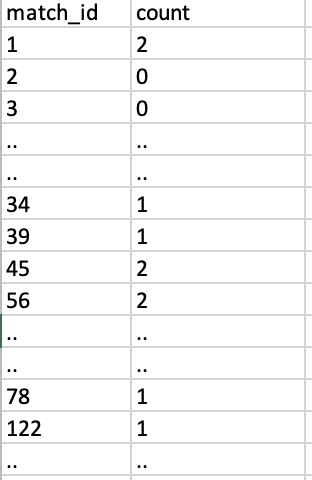
If a particular id is not found, then the count will be 0 in the output. I tried using for loop approach but it is quite slow.
def readData():
df = pd.read_excel(file_path)
pattern_match_count = [0] * 761
for index, row in df.iterrows():
matches = row["matches"]
for pattern_id in range(1, 762):
if(pattern_id in matches):
pattern_match_count[pattern_id - 1] = pattern_match_count[pattern_id - 1] 1
Is there any better approach with pandas to make the implementation faster?
CodePudding user response:
You can use the .explode() method to "explode" the lists into new rows.
def readData():
df = pd.read_excel(file_path)
return df.loc[:, "count"].explode().value_counts()
CodePudding user response:
You can use collections.Counter:
df = pd.DataFrame({"matches": [[1,2,3],[1,3,3,4]]})
#df:
# matches
#0 [1, 2, 3]
#1 [1, 3, 3, 4]
from collections import Counter
C = Counter([i for sl in df.matches for i in sl])
#C:
#Counter({1: 2, 2: 1, 3: 3, 4: 1})
pd.DataFrame(C.items(), columns=["match_id", "counts"])
# match_id counts
#0 1 2
#1 2 1
#2 3 3
#3 4 1
If you want zeros for match_ids that aren't in any of the matches, then you can update the Counter object C:
for i in range(1,762):
if i not in C:
C[i] = 0
pd.DataFrame(C.items(), columns=["match_id", "counts"])