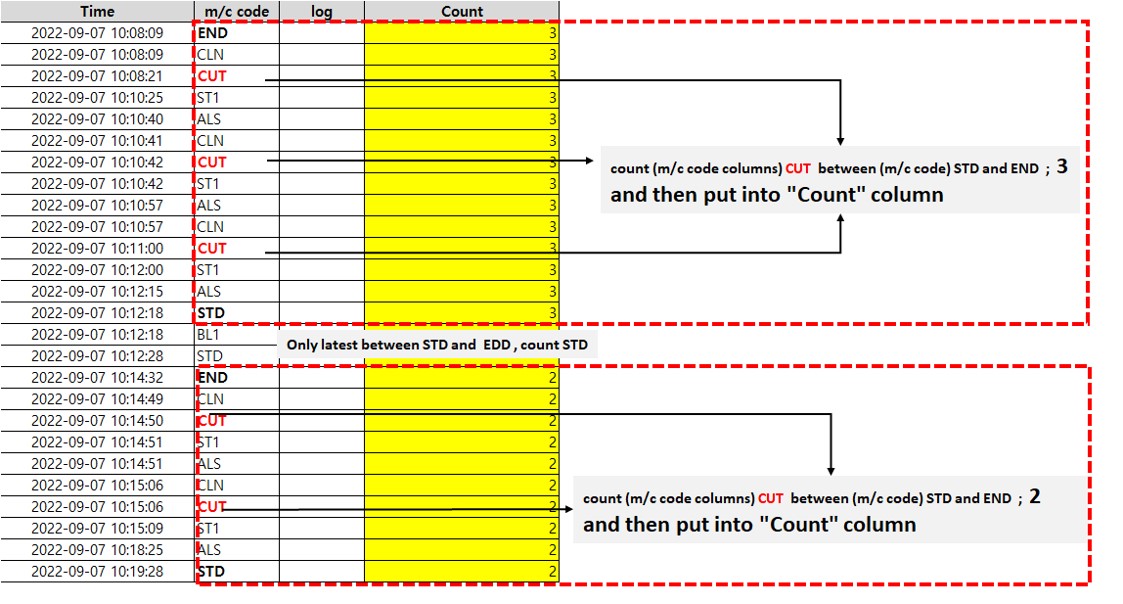
how to count between A and B in same columns dataframe (pandas)
count "CUT" in m/c code column between "STD" and "STD" which are repeated in many time in columns
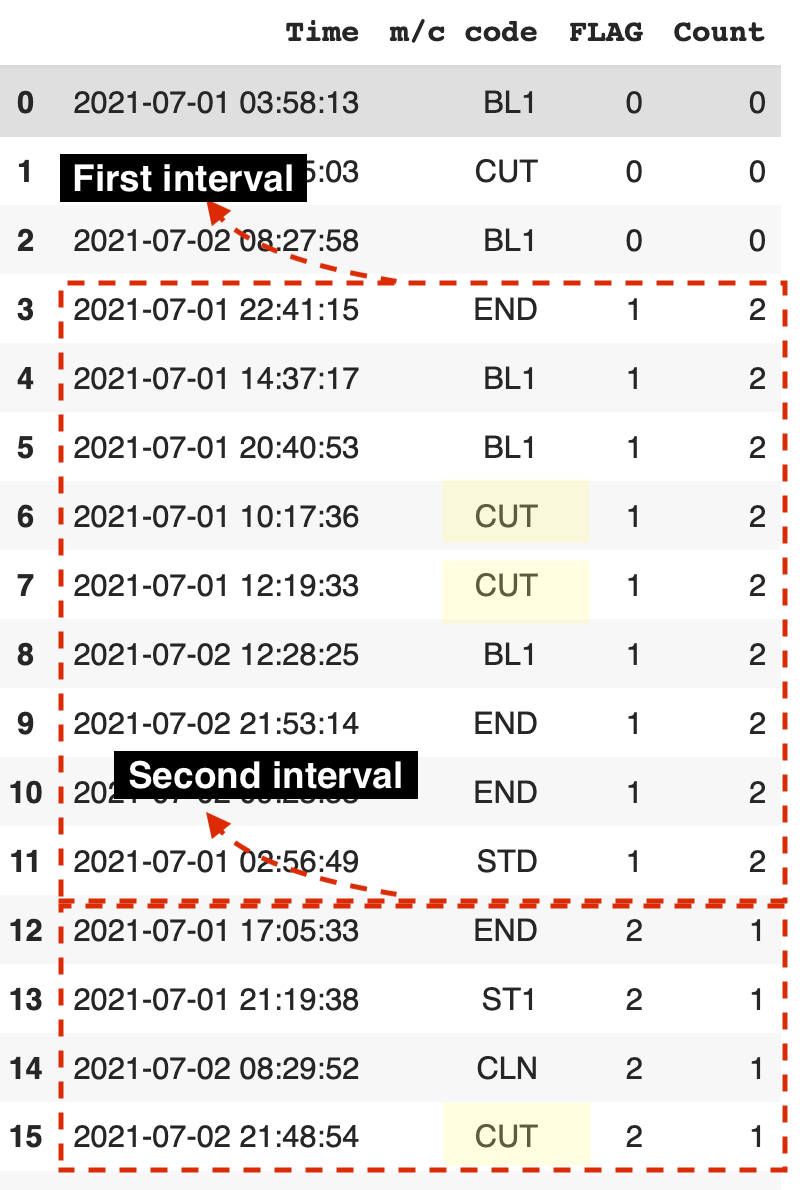
see below image attached
CodePudding user response:
There are obv many different ways.
One solution is this:
import pandas as pd
def c_counter(df, A, B, C):
starts = [i for i, x in enumerate(df['m/c code']) if x == 'A']
ends = [i for i, x in enumerate(df['m/c code']) if x == 'B']
df['Count'] = ''
for start, end in zip(starts, ends):
df['Count'][start:end] = sum(df['m/c code'][start:end] == 'C')
return(df)
df = pd.DataFrame({'m/c code': ['A', 'X', 'C', 'X', 'C', 'X', 'B', 'X', 'A', 'C', 'X', 'B']})
A = 'A'
B = 'B'
C = 'C'
c_counter(df, A, B, C)
Out:
m/c code Count
0 A 2
1 X 2
2 C 2
3 X 2
4 C 2
5 X 2
6 B
7 X
8 A 1
9 C 1
10 X 1
11 B
Next time, please make sure to include sample code.
CodePudding user response:
Another solution to your problem would be to create an auxiliary column that labels each interval. Then you can apply a groupby alongside the transform method, to perform the counting. Here's the code:
from __future__ import annotations
import pandas as pd
import numpy as np
# == Helper functions (Not part of the actual solution) =======================
# You can ignore these functions, as they don't actually are part of the
# solution, but rather a way to generate some data to test the implementation.
def random_dates(
start_date: str | pd.Timestamp,
end_date: str | pd.Timestamp,
size: int = 10,
) -> pd.DatetimeIndex:
"""Generate random dates between two dates.
Parameters
----------
start_date : str | pd.Timestamp
Start date.
end_date : str | pd.Timestamp
End date.
size : int, optional
Number of dates to generate, by default 10.
Returns
-------
pd.DatetimeIndex
Random dates.
Examples
--------
>>> random_dates("2020-01-01", "2020-01-31", size=5) # doctest: ELLIPSIS
DatetimeIndex(['2020-01-05', '2020-01-12', ...], dtype='datetime64[ns]', freq=None)
"""
start_u = pd.to_datetime(start_date).value // 10**9
end_u = pd.to_datetime(end_date).value // 10**9
return pd.to_datetime(np.random.randint(start_u, end_u, size), unit="s")
def generate_random_frame(
start_date: str | pd.Timestamp,
end_date: str | pd.Timestamp,
size: int = 10,
) -> pd.DataFrame:
"""
Generate a DataFrame to test the solution.
Parameters
----------
start_date : str | pd.Timestamp
Start date. Must be a string representing a date, like "YYYY-MM-DD",
or "YYYY-MM-DD HH:MM:SS". Optionally, can also be a pandas Timestamp
object.
end_date : str | pd.Timestamp
End date. Must be a string representing a date, like "YYYY-MM-DD",
or "YYYY-MM-DD HH:MM:SS". Optionally, can also be a pandas Timestamp.
size : int, default 10
Number of rows to generate.
Returns
-------
pd.DataFrame
DataFrame with random dates and random values. The resulting DataFrame
has the following columns:
- "Time": random datetimes between `start_date` and `end_date`.
- "m/c code": random strings from a set of 7 possible values:
"END", "CUT", "STD", "BL1", "ALS", "ST1", or "CLN".
"""
mc_code_choices = ["END", "CUT", "STD", "BL1", "ALS", "ST1", "CLN"]
return pd.DataFrame(
{
"Time": random_dates(start_date, end_date, size),
"m/c code": np.random.choice(mc_code_choices, size),
}
)
# == Solution ==================================================================
def flag_groups_and_count(
df: pd.DataFrame,
group_colname: str = "m/c code",
lowbound_value: str = "END",
upbound_value: str = "STD",
value_to_count: str = "CUT",
count_colname: str = "Count",
flag_colname: str = "FLAG",
) -> pd.DataFrame:
"""
Flag groups and count the number of times a specified value appears on each group.
Groups are defined by values between `lowbound_value` and `upbound_value`
in the column `group_colname`. The flag is set to 1 for the first group.
Subsequent groups are flagged as 2, 3, etc. Groups are flagged as 0
represent the absence of a group.
After flagging the groups, function counts the number of times
the value specified by the `value_to_count` parameter appears.
Parameters
----------
df : pd.DataFrame
DataFrame to flag.
group_colname : str, default "m/c code"
Column name to group by.
lowbound_value : str, default "END"
Value to start each group.
upbound_value : str, default "STD"
Value to end each group.
value_to_count : str, default "CUT"
Value to count inside the groupby.
count_colname : str, default "Count"
Name of the column to store the counts.
flag_colname : str, default "FLAG"
Name of the column to store each group.
Returns
-------
pd.DataFrame
Original DataFrame with the added flag column.
"""
# Set the initial parameters, used to control the creation of the groups.
current_group = 1 # The current group number.
flag_row = False # Indicates whether the current row should be flagged.
# Create the column that stores the group numbers.
# Set all values initially to 0
df[flag_colname] = 0
# Iterate over each row of the dataframe.
# - index: index of each row. Same values you find by calling df.index
# - row: a pandas Series object with the values of each row.
for index, row in df.iterrows():
# If the current row has a 'm/c code' value equal to 'END',
# then set the flag_row variable to True to indicate that
# the next rows should be set to `current_group` untill
# it finds a row with 'm/c code' value that equals to 'STD'.
if row[group_colname] == lowbound_value:
flag_row = True
# Does this row belong to a group? If so, set it to `current_group`.
if flag_row:
df.loc[df.index.isin([index]), flag_colname] = current_group
# If the current row has a 'm/c code' value equal to 'STD',
# then we reached the end of a group. Set the flag_row variable
# to False indicating that the next rows should not be flagged to a
# group.
if row[group_colname] == upbound_value:
# Did we reach the end of a group, or simply found another value
# equal to "STD" before the next interval starts?
# This is to avoid incrementing the group number when in fact we didn't
# reach a new interval.
if flag_row:
current_group = 1
flag_row = False
# Groupby 'm/c code' column values by the newly created flag column.
# Inside this groupby, use the `transform` method to count the number of
# times the value "CUT" appears inside each group.
# Store the count in a new column called "Count".
df[count_colname] = df.groupby(flag_colname, as_index=False)[
group_colname
].transform(lambda group: (group == value_to_count).sum())
# Same as:
# df["Count"] = df.groupby("FLAG", as_index=False)[
# "m/c code"
# ].transform(lambda group: (group == "CUT").sum())
# When the flag column is equal to 0, it means that there's no interval.
# Therefore, set such counts to 0. Intervals represent the rows with
# values for the 'm/c code' column between adjacent "END" and "STD" values.
df.loc[test_df[flag_colname] == 0, count_colname] = 0
# Same as: test_df.loc[test_df["FLAG"] == 0, "Count"] = 0
return df
# == Test our code =============================================================
# Parameters to use for generating test DataFrame:
start_date = "2021-07-01 00:00:00"
end_date = "2021-07-03 00:00:00"
# Generate test DataFrame
test_df = generate_random_frame(start_date, end_date, size=30)
# Call the function that defines the implementation to the problem.
test_df = test_df.pipe(flag_groups_and_count)
test_df
Here's a screenshot of the output: