I have the standard dataset from R called ToothGrowth. I have this R code that makes me two histograms of tooth growth in guinea pigs based by the different delivery methods:
vctooth <- ToothGrowth[1:30, c(3,1)]
ojtooth <- ToothGrowth[31:60, c(3,1)]
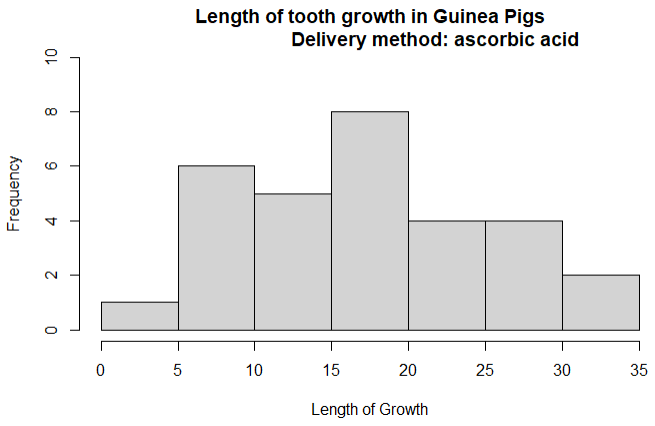
hist(vctooth$len, main = 'Length of tooth growth in Guinea Pigs
Delivery method: ascorbic acid',
xlab = "Length of Growth",
ylab="Frequency",
ylim=c(0,10),)
hist(ojtooth$len, main = 'Length of tooth growth in Guinea Pigs
Delivery method: orange juice',
xlab = "Length of Growth",
ylab="Frequency",
ylim=c(0,10),)
How can I specifically set different intervals and make histogram for the vctooth and ojtooth in Python Pandas?
Down below there is the ToothGrowth dataset:
"len","supp","dose"
4.2,"VC",0.5
11.5,"VC",0.5
7.3,"VC",0.5
5.8,"VC",0.5
6.4,"VC",0.5
10,"VC",0.5
11.2,"VC",0.5
11.2,"VC",0.5
5.2,"VC",0.5
7,"VC",0.5
16.5,"VC",1
16.5,"VC",1
15.2,"VC",1
17.3,"VC",1
22.5,"VC",1
17.3,"VC",1
13.6,"VC",1
14.5,"VC",1
18.8,"VC",1
15.5,"VC",1
23.6,"VC",2
18.5,"VC",2
33.9,"VC",2
25.5,"VC",2
26.4,"VC",2
32.5,"VC",2
26.7,"VC",2
21.5,"VC",2
23.3,"VC",2
29.5,"VC",2
15.2,"OJ",0.5
21.5,"OJ",0.5
17.6,"OJ",0.5
9.7,"OJ",0.5
14.5,"OJ",0.5
10,"OJ",0.5
8.2,"OJ",0.5
9.4,"OJ",0.5
16.5,"OJ",0.5
9.7,"OJ",0.5
19.7,"OJ",1
23.3,"OJ",1
23.6,"OJ",1
26.4,"OJ",1
20,"OJ",1
25.2,"OJ",1
25.8,"OJ",1
21.2,"OJ",1
14.5,"OJ",1
27.3,"OJ",1
25.5,"OJ",2
26.4,"OJ",2
22.4,"OJ",2
24.5,"OJ",2
24.8,"OJ",2
30.9,"OJ",2
26.4,"OJ",2
27.3,"OJ",2
29.4,"OJ",2
23,"OJ",2
The output should be like this:
CodePudding user response:
You can use iloc to set indexes:
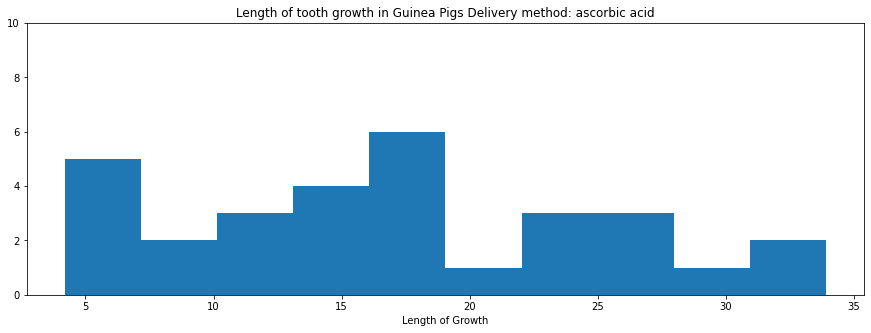
import matplotlib.pyplot as plt
plt.figure(figsize=(15, 5))
# you can filter the indexes with iloc
plt.hist(df.iloc[:30]['len'])
plt.xlabel("Length of Growth")
plt.title('Length of tooth growth in Guinea Pigs Delivery method: ascorbic acid')
plt.ylim((0, 10))
plt.show()
Output:
Edit for ylabel: plt.ylabel('Frequency')
CodePudding user response:
You can do it by inputting a list to bins parameter of hist method:
dt.hist(bins=[0, 0.5, 1.0])
For example on some random dataframe:
pd.DataFrame(random.random(100)).hist(bins=[0, 0.5, 1.0])