I have a log file with lines like this :
2022-10-20 14:23:06,709 [12] INFO XXXX.XXXX.XXXX.XXXX - XXXX XXXX, Added XXXX in XXXX for thread: XX, XXXX exists: XXX
I would like to create 6 columns, like this :
Column 1 : 2022-10-20
Column 2 : 14:23:06,709
Column 3 : [12]
Column 4 : INFO
Column 5 : XXXX.XXXX.XXXX.XXXX
Column 6 : XXXX XXXX, Added XXXX in XXXX for thread: XX, XXXX exists: XXX
but as you can see it's not possible by delimiting the elements with spaces. It creates 17 columns when I do it with spaces. Does anyone have any idea how to delimit the elements so that I can create the columns?
Thanks !
CodePudding user response:
you can try read_fwf() function.
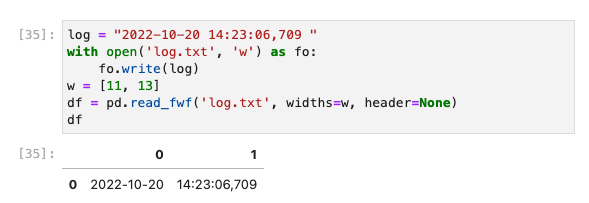
CodePudding user response:
Here is one way about it
we need a rule to apply to the log file when reading here
we can split on spaces but only first 5 spaces
lines=[]
# open the log file
with open("csv2.txt") as fi:
for line in fi:
line = re.split(r"\s ", line, 5) # split only 5 times per line
lines.append(line) # build a list of list
df=pd.DataFrame(lines) # create dataframe
df
0 1 2 3 4 5
0 2022-10-20 14:23:06,709 [12] INFO XXXX.XXXX.XXXX.XXXX - XXXX XXXX, Added XXXX in XXXX for thread: XX...
1 2022-10-21 14:23:06,709 [12] INFO XXXX.XXXX.XXXX.XXXX - XXXX XXXX, Added XXXX in XXXX for thread: XX...
2 2022-10-21 14:23:06,709 [12] INFO XXXX.XXXX.XXXX.XXXX - XXXX XXXX, Added XXXX in XXXX for thread: XX...