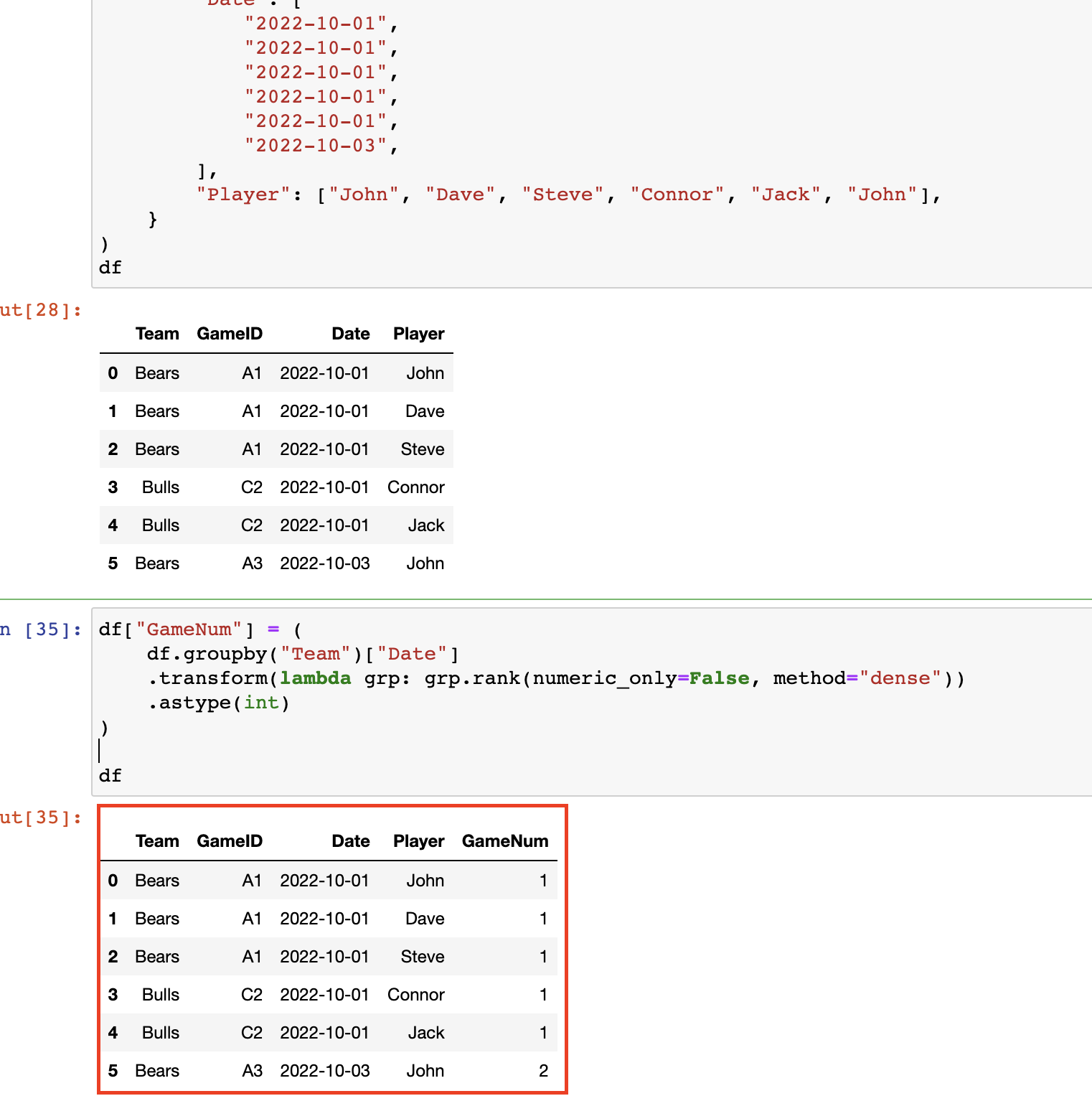
I have a dataframe in the following format (working with sports data):
| Team | Player | Date | GameID |
|---|---|---|---|
| Bears | John | 2022-10-01 | A1 |
| Bears | Dave | 2022-10-01 | A1 |
| Bears | Steve | 2022-10-01 | A1 |
| Bulls | Connor | 2022-10-01 | C2 |
| Bulls | Jack | 2022-10-01 | C2 |
| Bears | John | 2022-10-03 | A3 |
Basically, I want to be able to sort by team name and date, and add a column called GameNum that counts from 1 to 82 (82 games in the dataset for each team) based on the game number for the season, like below:
| Team | Player | Date | GameID | GameNum |
|---|---|---|---|---|
| Bears | John | 2022-10-01 | A1 | 1 |
| Bears | Dave | 2022-10-01 | A1 | 1 |
| Bears | Steve | 2022-10-01 | A1 | 1 |
| Bulls | Connor | 2022-10-01 | C2 | 1 |
| Bulls | Jack | 2022-10-01 | C2 | 1 |
| Bears | John | 2022-10-03 | A3 | 2 |
I can do this manually by taking a sub-dataframe of each unique team, sorting by game date, and then adding an iterator value from 1 to 82 and then unioning the results for each team, but I was wondering if there was a "cleaner" way to do this without resorting to for-loops and unioning based on teams.
CodePudding user response:
here is one way to do it
#create a dictionary of GameNum, with key being the index of the dataframe
d=dict(df.loc[~df.duplicated(subset=['Team','Date'])] # choose unique Team and Date
.groupby(['Team'], as_index=False) # groupby Team
.cumcount() 1) # create a count of Game
# map game number to Game based on index
df['GameNum']=df.index.map(d)
# ffill null values
df['GameNum'].ffill(inplace=True)
# convert game num to int
df['GameNum']=df['GameNum'].astype(int )
df
Team Player Date GameID GameNum
0 Bears John 2022-10-01 A1 1
1 Bears Dave 2022-10-01 A1 1
2 Bears Steve 2022-10-01 A1 1
3 Bulls Connor 2022-10-01 C2 1
4 Bulls Jack 2022-10-01 C2 1
5 Bears John 2022-10-03 A3 2
CodePudding user response:
I'm not really sure on the manual aspect you want to make cleaner but you can try below solution for your task.
It provides a basic setup for your problem - the only thing I've changed is data column, which is now named 'value' and contains string values.
import pandas as pd
data = {'team':["bears", "bears", "bears", "bulls", "bulls", "bears"], 'value':["a", "a", "a", "a", "c", "b"]}
df = pd.DataFrame(data, columns = ["team", "value"])
df_grouped = df.groupby('team')
df_team_list = [df_grouped.get_group(x) for x in df_grouped.groups]
df_team_list_with_game_num = list()
for df_team in df_team_list:
df_sorted = df_team.sort_values(by=["value"])
unique_values = df_sorted["value"].unique()
game_num_map = dict()
for i, value in enumerate(unique_values):
game_num_map[value] = i
df_sorted["game_num"] = df_sorted["value"].apply(lambda x: game_num_map[x])
df_team_list_with_game_num.append(df_sorted)
df_with_game_num = pd.concat(df_team_list_with_game_num)
print(df_with_game_num)
CodePudding user response:
You could also try something like:
df["GameNum"] = (
df.groupby("Team")["Date"]
.transform(lambda grp: grp.rank(numeric_only=False, method="dense"))
.astype(int)
)
Output: