I am trying to count values for multiple columns including values that might not occur in the column. Given example data frame:
foo = pd.DataFrame({'A':[False,False,True], 'B':[None, False, True], 'C': [None, None, None]})
my final result would look like:
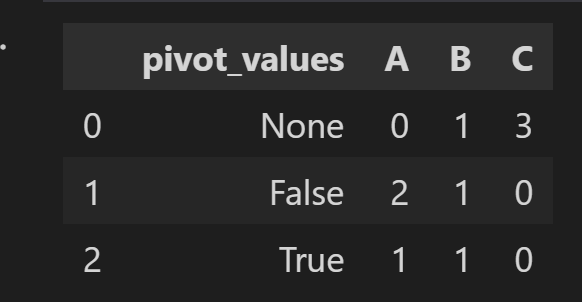
.value_counts() would not work here for me since it will miss some values plus it works primary on pd.Series. So far I tried pivot table but without success:
# returns KeyError: False
foo.pivot_table(index=[False, True, None], columns=foo.columns, aggfunc='count')
How can pandas count all occurrences for specified values in multiple columns ?
CodePudding user response:
bar = foo.melt(var_name='pivot_values').replace({None: 'None'})
# for some reason, even using "dropna=False" in crosstab still removes None
out = (pd.crosstab(bar['pivot_values'], bar['variable'], dropna=False)
.reset_index().rename_axis(columns=None)
)
Output:
pivot_values A B C
0 False 2 1 0
1 True 1 1 0
2 None 0 1 3