Im trying to put into list two seperate column from an input file but they are all indexed the same how do i fix this.
name = []
income = []
with open('region-income.dat') as f:
parse = f.readlines()[8:]
for x in parse:
name.append(x.split(' ')[0])
print (name)
this code produces this outcome
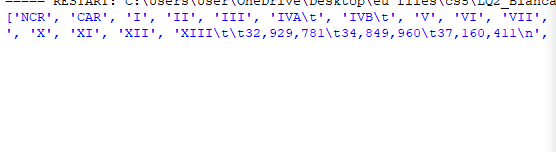
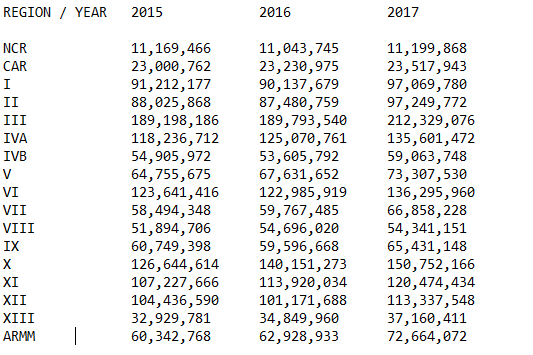
from this input file
CodePudding user response:
That should do it ?
name = []
income = []
with open('region-income.dat') as f:
parse = f.readlines()[8:]
for x in parse:
row = x.split()
name.append(row[0])
income.append(row[1])
print(name)
print(income)
It seems the XIII line is separated with tabs (\t) instead of spaces so I recommend just using split() which will split on all space-like characters.
Then the second column should just correspond to the second value of x.split() (stored into row) so we access it with row[1].