I have a txt file with the following content:
ID1;ID2;TIME;VALUE
1000;100;012021;12
1000;100;022021;4129
1000;100;032021;128
1000;100;042021;412
1000;100;052021;12818
1000;120;022021;4129
1000;100;062021;546
1000;100;072021;86
1000;120;052021;12818
1000;100;082021;754
1000;100;092021;2633
1000;100;102021;571
1000;120;092021;2633
1000;100;112021;2233
1000;100;122021;571
1000;120;012021;12
1000;120;032021;128
1000;120;042021;412
1000;120;062021;546
1000;120;072021;86
1000;120;082021;754
1000;120;102021;571
1000;120;112021;2233
1000;120;122021;571
1000;100;012022;12
1000;100;022022;4129
1000;120;022022;4129
1000;120;032022;128
1000;120;042022;412
1000;100;032022;128
1000;100;042022;412
1000;100;052022;12818
1000;100;062022;546
1000;100;072022;86
1000;100;082022;754
1000;120;072022;86
1000;120;082022;754
1000;120;092022;2633
1000;120;102022;571
1000;100;092022;2633
1000;100;102022;571
1000;100;112022;2233
1000;100;122022;571
1000;120;012022;12
1000;120;052022;12818
1000;120;062022;546
1000;120;112022;2233
1000;120;122022;571
I need to make aggregates of time (half year, total year), using the items from column time, which have the same ID1, ID2 and sum up the values.
The output should look like this:
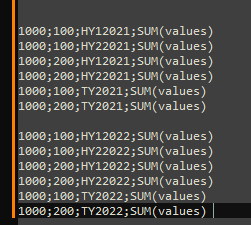
I would appreciate your help! This is what I have so far for half year: #already sorted by time
data=open("file.txt").readlines()
count = 0
for line in data:
count = 1
for n in range(count - 1, len(data), 6):
subList = [data[n:n 6]]
break
CodePudding user response:
I'm far from being a Python expert but how about something like:
dd = defaultdict(lambda: [])
rows = [elems for elems in [line.strip().split(';') for line in data[1:]]]
for row in rows:
mm = row[2][:2]
yy = row[2][2:]
vv = int(row[3])
key = (row[0], row[1], yy)
dd[key].append([mm, yy, vv])
# print("Total of all values", sum(int(row[3]) for row in rows))
for k, v in dd.items():
h1 = sum(c[2] for c in v if c[0] <= '06')
h2 = sum(c[2] for c in v if c[0] > '06')
tt = sum(c[2] for c in v)
# or, much more simply, tt = h1 h2
# print(k[0], k[1], k[2], "H1:", h1, "H2:", h2, "TT:", tt)
print(f"{k[0]};{k[1]};HY1{k[2]};{h1}")
print(f"{k[0]};{k[1]};HY2{k[2]};{h2}")
print(f"{k[0]};{k[1]};TY{k[2]};{tt}")
Seems to give correct results for the data supplied. Might not be efficient if you have huge amounts of data. YMMV.
CodePudding user response:
This is a task that is very well suited for the pandas library, which is designed to work with tabular data. A way to do this in pandas would be something like this:
import pandas as pd
# Read the data from the textfile (here I saved it as data.csv).
# Make sure the TIME column is not read as an integer by declaring
# dtype={'TIME': object}, because this would omit the leading zeroes, which
# we need for conversion to datetime object
df = pd.read_csv('data.csv', delimiter=';', dtype={'TIME': object})
# Convert TIME column to datetime
df['TIME'] = pd.to_datetime(df['TIME'])
# Create new column with year
df['Y'] = df['TIME'].dt.year
# Create new column with halfyear (1 = first halfyear, 2 = second halfyear)
df['HY'] = df['TIME'].dt.month.floordiv(7).add(1)
After this, your table looks like this:
df.head() # Just show the first couple of rows
ID1 ID2 TIME VALUE Y HY
0 1000 100 2021-01-20 12 2021 1
1 1000 100 2021-02-20 4129 2021 1
2 1000 100 2021-03-20 128 2021 1
3 1000 100 2021-04-20 412 2021 1
4 1000 100 2021-05-20 12818 2021 1
Getting the table into the desired format takes a bit of work, but grouping and aggregating then becomes really easy. You can then also perform other grouping and aggregating operations as you please without having to code it all from hand.
To group by year and calculate the sum:
df.groupby(['ID1', 'ID2', 'Y']).sum()
ID1 ID2 Y VALUE
1000 100 2021 24893
1000 100 2022 24893
1000 120 2021 24893
1000 120 2022 24893
To group by halfyear and calculate the sum:
df.groupby(['ID1', 'ID2', 'Y', 'HY']).sum()
ID1 ID2 Y HY VALUE
1000 100 2021 1 18045
1000 100 2021 2 6848
1000 100 2022 1 18045
1000 100 2022 2 6848
1000 120 2021 1 18045
1000 120 2021 2 6848
1000 120 2022 1 18045
1000 120 2022 2 6848