I'm trying to use filter to find those 'title' that are not in list_A.
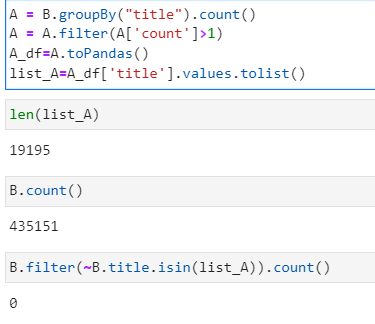
A = B.groupBy("title").count()
A = A.filter(A['count'] > 1)
A_df = A.toPandas()
list_A = A_df['title'].values.tolist()
B.filter(~B.title.isin(list_A)).count()
However, I get an empty dataframe back (count is 0)
It works well when I use 'is in':

Why this happened and how can I solve this?
I tried:
B=B.na.drop(subset=["title"])
B.filter(~B.title.isin(list_A)).count()
print(B.filter(~B.title.isin(list_A) | B.title.isNull()).count())
It still returns 0.
CodePudding user response:
It may be because other "title" values are null.
B = spark.createDataFrame([('x',), ('x',), (None,)], ['title'])
A = B.groupBy("title").count()
A = A.filter(A['count'] > 1)
A_df = A.toPandas()
list_A = A_df['title'].values.tolist()
print(B.filter(~B.title.isin(list_A)).count())
# 0
print(B.filter(B.title.isin(list_A)).count())
# 2
If you really need list_A, you shouldn't go to Pandas for it.
You can either use
collectA = B.groupBy("title").count().filter(F.col('count') > 1) list_A = [x.title for x in A.collect()] print(list_A) # ['x', None]or
collect_setlist_A = (B .groupBy("title").count() .groupBy((F.col('count') > 1).alias('_c')).agg( F.collect_set('title').alias('_t') ).filter('_c') .head()[1] ) print(list_A) # ['x']
Finally, to translate your current query to PySpark, you should use window functions.
Input:
from pyspark.sql import functions as F, Window as W
B = spark.createDataFrame(
[('x', 'Example'),
('x', 'Example'),
('x', 'not_example'),
('y', 'not_example'),
(None, 'not_example'),
(None, 'Example')],
['title', 'journal'])
Your current script:
A = B.groupBy("title").count()
A = A.filter(A['count'] > 1)
A_df = A.toPandas()
list_A = A_df['title'].values.tolist()
B.filter(((B.title.isin(list_A))&(B.journal!="Example"))|(~B.title.isin(list_A)))
Suggestion:
B_filtered = (B
.withColumn('A_cnt', F.count('title').over(W.partitionBy('title')))
.filter("(A_cnt > 1 and journal != 'Example') or A_cnt <= 1")
.drop('A_cnt')
)
B_filtered.show()
# ----- -----------
# |title| journal|
# ----- -----------
# | null|not_example|
# | null| Example|
# | x|not_example|
# | y|not_example|
# ----- -----------