I have a "pandas.MultiIndex.from_product" data-frame from which I want to slice some data.
For these slices I know the (multi-) index.
The known index does not necessarily exist in the data-frame, it might be lower for the start-index (b1) or higher for the end-index (b2), see code slice1.
Here is a minimal example of my problem.
import pandas as pd
ind = pd.MultiIndex.from_product([range(3), range(3)], names=["a", "b"])
df = pd.DataFrame(range(0,9999,1111), columns=["values"], index=ind)
idx = pd.IndexSlice
slice1 = df.loc[idx[0:1, 1:3],:]
slice2 = df.loc[idx[0:2, 1:0],:]
In the pictures you see the data-frame df, slice1 and the expected slice2. As long as b1<b2 my code works perfectly fine but when b1>b2 as it is in slice2 it returns an empty data-frame.
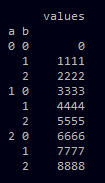
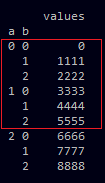
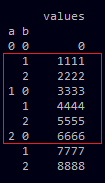
Is there a way to make this working? BTW, I saw this post here: Select rows in pandas MultiIndex DataFrame but I don't think it answers this question.
CodePudding user response:
Answering my own question. I tried it way too complicated, this is the answer:
slice2 = df.loc[(0,1):(2,0),:]
CodePudding user response:
Even shorter:
slice2 = df[(0,1):(2,0)]