I want to access some files stored in dbfs location of ADB-1(Azure databricks) workspace from ADB-2 workspace. Just wanted to understand if its possible to query another workspace dbfs storage. I tried googling this question a lot but so far no luck. Please help!!
For example - in ADB-1 workspace i have file store in /dbfs/FileStore/Zone1/File1.csv . To read File1.csv from ADB-2 workspace, how can this be done? Any suggestions
CodePudding user response:
There is an API in Databricks i.e., DBFS 2.0 where there is a GET method. But there are few limitations.
- Look at the following demonstration. Let's say dbfs1 is where the required files are present. You can use the below code to read the file from 2nd Databricks notebook.
import requests
import json
my_json = { "path": "/FileStore/sample1.csv", "offset": 0, "length": 1000000 } #path is from dbfs1
auth = {"Authorization": "Bearer <access_token>"}
#url of databricks workspace where the file is present
response = requests.get('https://<databricks_workspace_url>/api/2.0/dbfs/read', json = my_json, headers=auth).json()
#print(response)
- The returned response is object where the file data is returned as base64 encoded string.
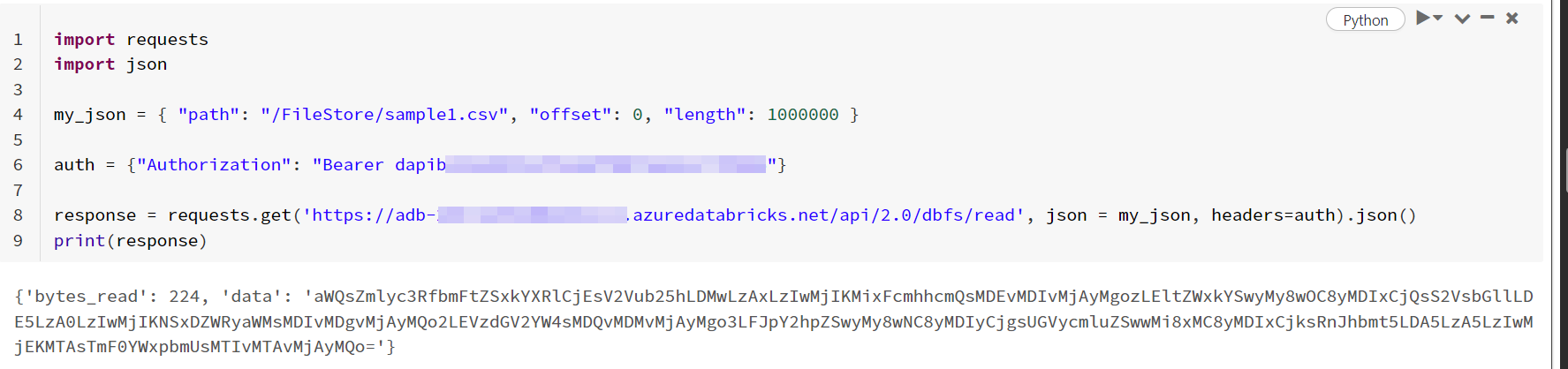
- You can use the following code to decode the above returned encoded string.
import base64
encoded_data = response['data']
encoded = encoded_data.encode('ascii')
to_decode = base64.b64decode(encoded)
decoded_data = to_decode.decode('ascii')
#print(decoded_data)

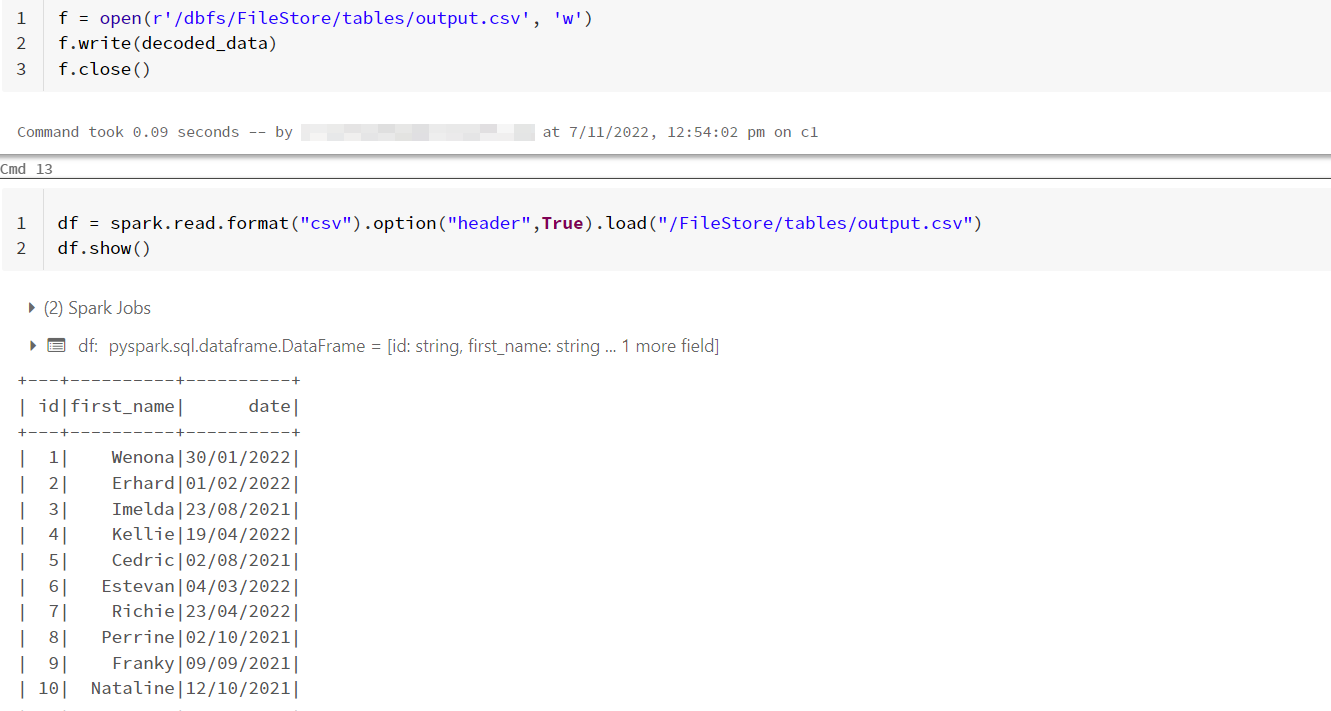
- Since the
decoded_datais a string, I wrote it as text file calledoutput.csvand read the file as a csv file using the following code.
f = open(r'/dbfs/FileStore/tables/output.csv', 'w')
f.write(decoded_data)
f.close()
df = spark.read.format("csv").option("header",True).load("/FileStore/tables/output.csv")
df.show()
NOTE:
This process does not work for parquet files. For other file formats, the procedure changes (above is an example for csv file, process is different for json or other format files).
There is also a size limitation of 1MB specified in the Microsoft documentation for using the DBFS
readAPI.So, instead of doing this, you can either download the file to local computer and re-upload the file to 2nd databricks dbfs or store the file in a storage account from where it can be easily accessible.