I have table towns which is main table. This table contains so many rows and it became so 'dirty' (someone inserted 5 milions rows) that I would like to get rid of unused towns.
There are 3 referent table that are using my town_id as reference to towns.
And I know there are many towns that are not used in this tables, and only if town_id is not found in neither of these 3 tables I am considering it as inactive and I would like to remove that town (because it's not used).
Print screen of my story:
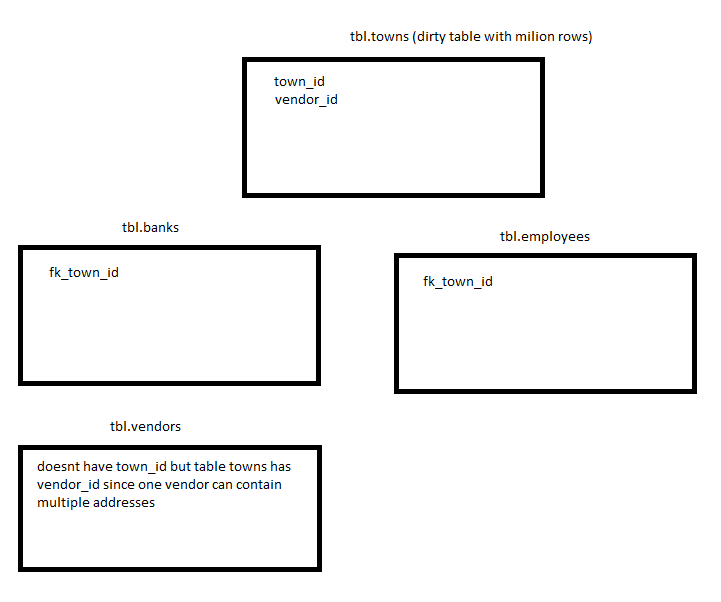
as you can see towns is used in this 2 different tables:
- employees
- offices
and for table * vendors there is vendor_id in table towns since one vendor can have multiple towns.
so if vendor_id in towns is null and town_id is not found in any of these 2 tables it is safe to remove it :)
I created a query which might work but it is taking tooooo much time to execute, and it looks something like this:
select count(*)
from towns
where vendor_id is null
and id not in (select town_id from banks)
and id not in (select town_id from employees)
So basically I said, if vendor_is is null it means this town is definately not related to vendors and in the same time if same town is not in banks and employees, than it will be safe to remove it.. but query took too long, and never executed successfully...since towns has 5 milions rows and that is reason why it is so dirty..
In face I'm not able to execute given query since server terminated abnormally..
Here is full error message:
ERROR: server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request.
Any kind of help would be awesome Thanks!
CodePudding user response:
You can try an JOIN on big tables it would be faster then two IN
you could also try UNION ALL and live with the duplicates, as it is faster as UNION
Finally you can use a combined Index on id and vendor_id, to speed up the query
CREATE TABLe towns (id int , vendor_id int)
CREATE TABLE
CREATE tABLE banks (town_id int)
CREATE TABLE
CREATE tABLE employees (town_id int)
CREATE TABLE
select count(*)
from towns t1 JOIN (select town_id from banks UNION select town_id from employees) t2 on t1.id <> t2.town_id
where vendor_id is null
| count |
|---|
| 0 |
SELECT 1
CodePudding user response:
You can join the tables using LEFT JOIN so that to identify the town_id for which there is no row in tables banks and employee in the WHERE clause :
WITH list AS
( SELECT t.town_id
FROM towns AS t
LEFT JOIN tbl.banks AS b ON b.town_id = t.town_id
LEFT JOIN tbl.employees AS e ON e.town_id = t.town_id
WHERE t.vendor_id IS NULL
AND b.town_id IS NULL
AND e.town_id IS NULL
LIMIT 1000
)
DELETE FROM tbl.towns AS t
USING list AS l
WHERE t.town_id = l.town_id ;
Before launching the DELETE, you can check the indexes on your tables. Adding an index as follow can be usefull :
CREATE INDEX town_id_nulls ON towns (town_id NULLS FIRST) ;
Last but not least you can add a LIMIT clause in the cte so that to limit the number of rows you detele when you execute the DELETE and avoid the unexpected termination. As a consequence, you will have to relaunch the DELETE several times until there is no more row to delete.