This is a small demo, face recognition by unknown face image in the video image to,
The Author chengstone
E-mail 69558140 @163.com
This Demo to complete the beginning of the end of March 4, 2017,
Code, please see the blog: http://blog.csdn.net/chengcheng1394/article/details/77817194
Programs using the model parameters of VGG, there is no upload, need you download other, a total of two files (VGG_FACE_deploy. Prototxt, VGG_FACE. Caffemodel) on VGGFace directory, I was download address below: http://101.96.8.164/www.robots.ox.ac.uk/~vgg/software/vgg_face/src/vgg_face_caffe.tar.gz
Is in the image below for the output:
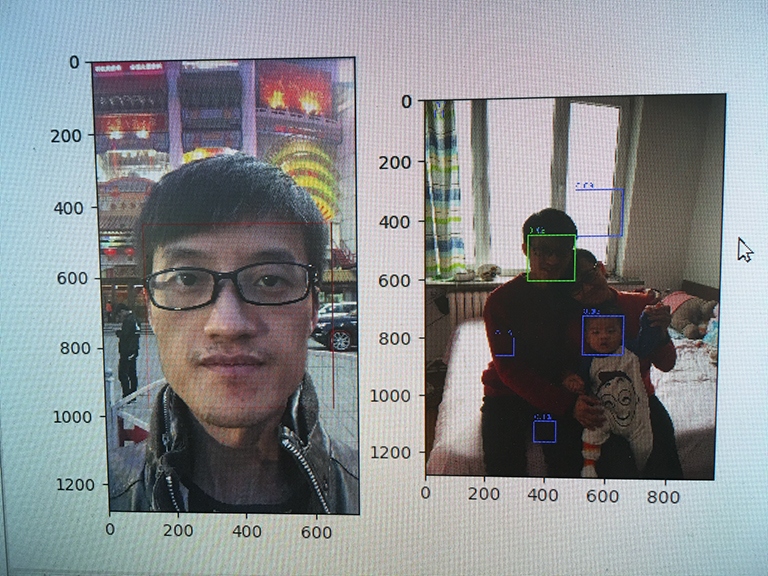
Finding out the video output in the folder out, there are four avi files: https://github.com/chengstone/FindFaceInVideo/tree/master/VGGFace/out,
The directory structure:
Facedetect. Py: main program, the attention when use will rewrite into your local path to the inside,
Face_recognition. Py: provide the function of the two face feature comparison, the program from https://github.com/HolmesShuan/DeepID-I-Reimplement, I had the change, can anyone interested in BeyondCompare difference,
Lfw_test_deal. Py: from https://github.com/hqli/face_recognition, in fact, if not used, may be I used to do the test, at that time, a little can't remember,
Out folders: used to store the output results of the video for
TMP. JPG: is in the picture according to provide to get the output of the faces of people,
A folder named after picture filename: IMG_3588, qingyansi etc folder is to face recognition test when the output of the image, only focus on whether to find a face, not to judge whether the person we are looking for
Chengshd folders: used to store my personal test cases, include pictures and video,
Finding out the targets. TXT: written image path list,
Positive_pairs_path. TXT: is face_recognition py of test data, provide each line is used to compare the two pictures path, for example: 2-1. 2-2. PNG PNG, test function face_recog_test read each pair of pictures, calculates the parameters of each image best: Accuracys, Thresholds, the Precisions and Recalls of F1Score,
Other documents: basically I test the output of
The use of the program:
This procedure will use another program, please download with https://github.com/chengstone/SeetaFaceEngine
This Demo is divided into two project: SeetaFaceEngine and VGGFace, including SeetaFaceEngine from https://github.com/seetaface/SeetaFaceEngine, we only use the FaceDetection and FaceAlignment, is mainly used to do in dispute for pictures of face detection and orientation, including FaceAlignment/SRC/test/face_alignment_test CPP I had the change, make the program to support a variety of face recognition in the command line way, VGGFace used for the comparison of face, there are also using the opencv face detection, mainly used in many face detection in the target image,
Run:
The environment depends upon, please install in advance:
Opencv2 caffe Python2.7
Second, the build order:
1. Compile SeetaFaceEngine FaceDetection below first, compiling method can refer to the readme inside, command is roughly:
The mkdir build
CD build
Cmake..
Make
2. Then compiled file (in my computer after been compiled for example is facedet_test libseeta_facedet_lib. Dylib this two files), FaceDetection. H file face_detection. J h, seeta_fa_v1. 1. Bin and seeta_fd_frontal_v1. 0. Several bin file copy to FaceAlignment build directory, and then compile, compile command to build FaceDetection,
The mkdir build
CD build
Cmake..
Make
After been compiled file names (in my computer after been compiled, for example) : fa_test
3. The main use is FaceAlignment, this program command line format is:
First: fa_test source images full path save the target folder path [picture size changing pixels]
The image size changes of pixels can be omitted, omit the default is not the size of the zoom pictures,
Example: fa_test/path/to/123 JPG/path/to/folder 32
The image 123 JPG identified human face image output to/path/to/folder folder, after scaling the size of the size is 32 * 32,
The second: fa_test save the source image file path the full path list
(save the source image file path the full path list] is a text file, there is some line the first command format string, for batch identification pictures,
Example: fa_test/path/to/image. TXT
One image. TXT in content similar to the following content, can be a line can also be more line:
/Users/chengstone/Downloads/ML/att_faces/s40/9. JPG/Users/chengstone/Downloads/ML/att_faces_new/s40 64
/Users/chengstone/Downloads/ML/att_faces/s40/8. JPG/Users/chengstone/Downloads/ML/att_faces_new/s40 64
/Users/chengstone/Downloads/ML/att_faces/s40/7. JPG/Users/chengstone/Downloads/ML/att_faces_new/s40 64
/Users/chengstone/Downloads/ML/att_faces/s40/6. JPG/Users/chengstone/Downloads/ML/att_faces_new/s40 64
This program can not accurately recognize faces, sometimes,,
The third: fa_test
If not the incoming parameters, the default in the application reads the image under the current path. TXT file, file formats, see instructions above, this is the use of this Demo.
Three, video/picture to:
Main code in VGGFace facedetect. Py, used here the caffe VGG model is used for face feature extraction and feature comparison, because my own training model accuracy is too low (DeepID model, may be I don't have a good implementation, and I don't enough the training set), so we have to use VGG open model parameters,
Facedetect. Py method of use:
1. To modify VGGFace/the targets first. TXT file, there is a list of image path, each image must be only one person, if there is only one picture means only to find that a person, is written for someone I say, more than one word is looking for more than one person in the video and pictures,
2. Facedetect. Py command line parameters:
Python./facedetect. Py - the content images and video of the full path
One/pictures and video of the full path is the goal we want to find,
Example 1: python./facedetect. Py - the content/path/to/123 JPG
Example 2: python./facedetect. Py - the content/path/to/456. Mov
Recognition process:
Me explain a concept, the targets. TXT file list is to find a person, can be a also can be more than one person, is a photo of me, for example, means in the video or pictures to find me, find basis is according to the targets. TXT file to find my photo,
For example:/home/chengshd/ML/caffe - master/examples/VGGFace/chengshd/IMG_3588 JPG
Then facedetect. Py will call fa_test first, will the targets. The photos of the specified characters in the TXT file to do face recognition, is to find the face in the photo first, facedetect. Py will write the parameters used in the call fa_test into fa_test directory at the same level of the image. TXT file,
For example:/home/chengshd/ML/caffe - master/examples/VGGFace/chengshd/IMG_3588 JPG/home/chengshd/ML/caffe - master/examples/VGGFace/chengshd/IMG_3588 224
Results is to recognize the face picture on to the targets. The TXT file written to image file name as a directory directory,
For example: VGGFace/IMG_3588: IMG_3588_crop_224_0_145_460_652_967. JPG file is fa_test identify faces,
Then use just fa_test identify faces, according to call facedetect. Py the incoming parameters, for in the image or video,
Here facedetect. Py use of opencv cv2. CascadeClassifier do face recognition,
You will ask why I use two different way to recognize faces, I found cv2. After many tests CascadeClassifier and SeetaFace face recognition effect is not very perfect, this combination can also use,
, of course, there must be a better way to replace the current face recognition scheme, such as the convolution of the neural network approach to face recognition, this I have no further to do,
nullnullnullnullnullnullnullnullnullnullnullnullnullnullnull