Im trying to deal with some timeseries data that looks like this. As you can see the data is monthly, but some dates are at EOM, some at BOM and some simply a month name:
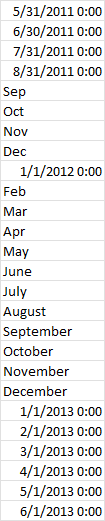
The solution i thought of was: assuming this is monthly data and that i know the start and end dates, i would like to create a date range from that start and end date and re-assign to the dataframe as the index. however, when i run this code:
pd.date_range('11/30/2020','03/01/2021', freq='MS')
I end up with this:
DatetimeIndex(['2020-12-01', '2021-01-01', '2021-02-01', '2021-03-01'], dtype='datetime64[ns]', freq='MS')
This is starting at December instead of november, so one less row than i expect. Why is this happening and what is a good solution here?
UPDATE
doing something like the following solves the problem for me
pd.date_range(pd.to_datetime('11/30/2020').to_period('M').to_timestamp(),'03/01/2021', freq='MS')
Im fine with that - but are there better ways to solve these kind of date issues?
CodePudding user response:
You need to have a start date that is compatible with the chosen freq. So for example 2020-11-01 for freq='MS' (month start).
If you don't have control over the first date (but know for sure it is a date), you can "truncate" it down to month start:
t_str = '11/30/2020'
ix = pd.date_range(pd.Timestamp(t_str).normalize().replace(day=1), freq='MS', periods=5)
>>> ix
DatetimeIndex(['2020-11-01', '2020-12-01', '2021-01-01', '2021-02-01',
'2021-03-01'],
dtype='datetime64[ns]', freq='MS')
Note BTW that it's safer to give one date (start or end) and a number of periods (the desired length of your index). That way, you know the length will be correct.
CodePudding user response:
When you use freq="MS" inside pd.date_range, pandas understands that you wish to create a range of dates with a month start frequency. The reason why it starts with '2020-12-01' is because December is the first start of a month that occurs, given '11/30/2020' as the start date. If you wish to include November in your DatetimeIndex, you could use relativedelta function from dateutil package.
To install dateutil, run the following command inside your console:
pip install python-dateutil
Then to include November in your DatetimeIndex, you can do something like this:
import pandas as pd
from dateutil.relativedelta import relativedelta
pd.date_range(
pd.Timestamp('11/30/2020') - relativedelta(day=1),
# ^------------------^
# |
# -- This ensures that your
# start date is November first.
'03/01/2021',
freq='MS',
)
# Returns:
#
# DatetimeIndex(['2020-11-01', '2020-12-01', '2021-01-01', '2021-02-01',
# '2021-03-01'],
# dtype='datetime64[ns]', freq='MS')
Regarding your difficult to 'normalize' dates, you could try using something like this to normalize it:
import pandas as pd
from dateutil.relativedelta import relativedelta
# Your example data
sample_data = [
"5/31/2011 0:00",
"6/31/2011 0:00",
"7/31/2011 0:00",
"8/31/2011 0:00",
"Sep",
"Oct",
"Nov",
"Dec",
"1/1/2012 0:00",
"Feb",
"Mar",
"Apr",
"May",
"June",
"July",
"August",
"September",
"October",
"November",
"December",
"1/1/2013 0:00",
"2/1/2013 0:00",
"3/1/2013 0:00",
"4/1/2013 0:00",
"5/1/2013 0:00",
"6/1/2013 0:00",
]
# Converting sample data values into `datetime64[ns]`
sample_series = pd.to_datetime(sample_data, errors = "coerce")
# ^---------------^
# |
# -- Using this option,
# pandas converts any
# "un-normalizable" date into
# `pd.NaT`
print(sample_series)
# Prints:
#
# DatetimeIndex(['2011-05-31', 'NaT', '2011-07-31', '2011-08-31',
# 'NaT', 'NaT', 'NaT', 'NaT',
# '2012-01-01', 'NaT', 'NaT', 'NaT',
# 'NaT', 'NaT', 'NaT', 'NaT',
# 'NaT', 'NaT', 'NaT', 'NaT',
# '2013-01-01', '2013-02-01', '2013-03-01', '2013-04-01',
# '2013-05-01', '2013-06-01'],
# dtype='datetime64[ns]', freq=None)
# Create your range of dates using the minimum and maximum values of `sample_series`:
pd.date_range(sample_series.min() - relativedelta(day=1), sample_series.max(), freq='MS')
# Returns:
#
# DatetimeIndex(['2011-05-01', '2011-06-01', '2011-07-01', '2011-08-01',
# '2011-09-01', '2011-10-01', '2011-11-01', '2011-12-01',
# '2012-01-01', '2012-02-01', '2012-03-01', '2012-04-01',
# '2012-05-01', '2012-06-01', '2012-07-01', '2012-08-01',
# '2012-09-01', '2012-10-01', '2012-11-01', '2012-12-01',
# '2013-01-01', '2013-02-01', '2013-03-01', '2013-04-01',
# '2013-05-01', '2013-06-01'],
# dtype='datetime64[ns]', freq='MS')
Warning: the above code assumes that the first and last dates from your data are represented as "parseable" dates. In other words,
if you have a list of dates like this: ["Apr", "5/31/2011 0:00", "6/31/2011 0:00", "7/31/2011 0:00", "8/31/2011 0:00", "September"], the above code would create a DatetimeIndex that starts at '2011-05-01', and ends at '2011-08-01'.