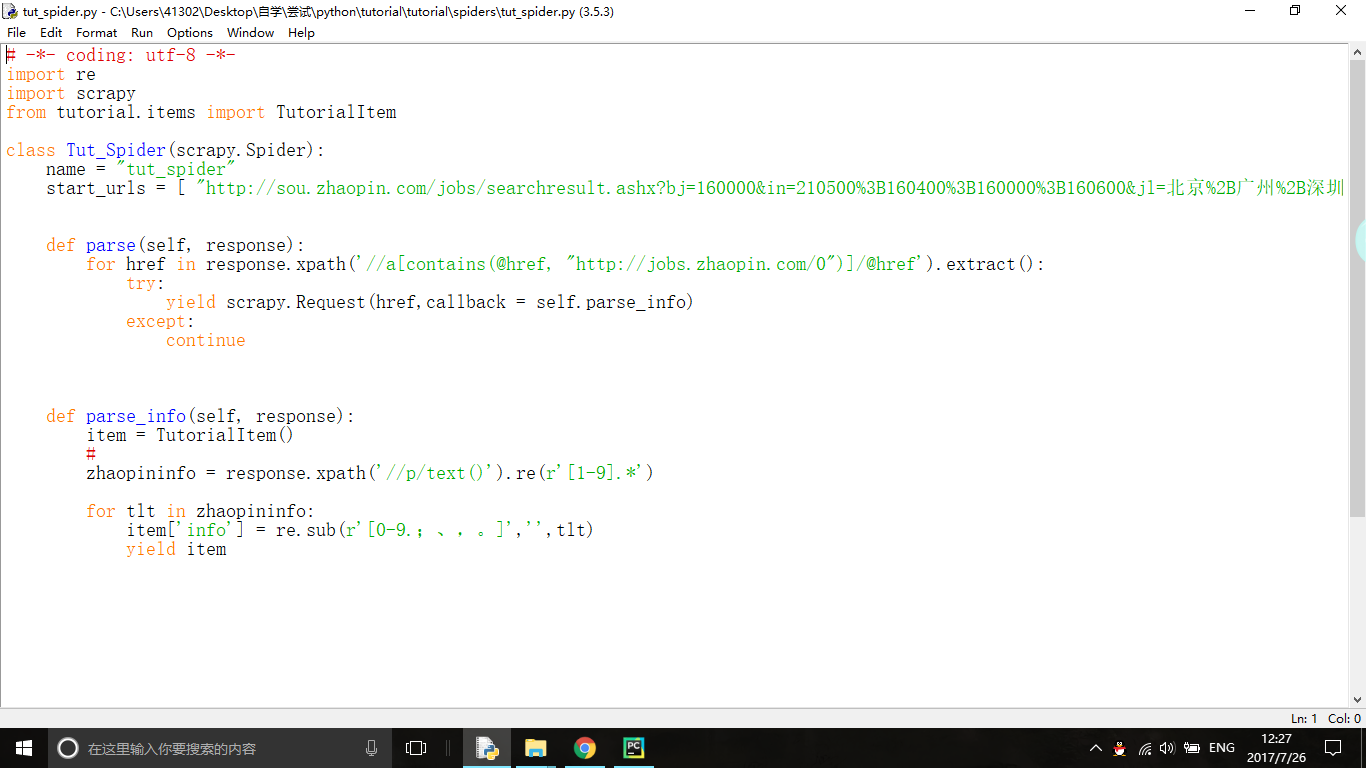
this is spiders function
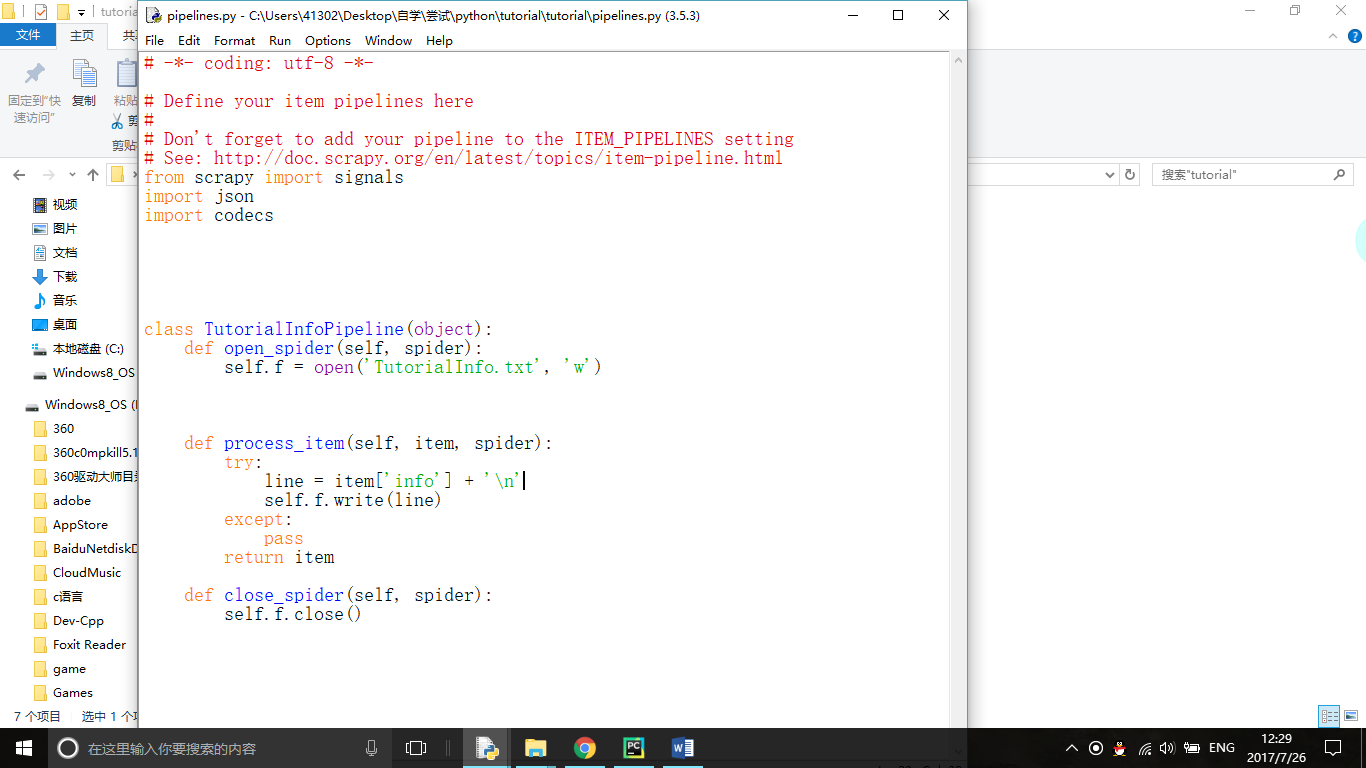 this is itempipeline file
this is itempipeline file 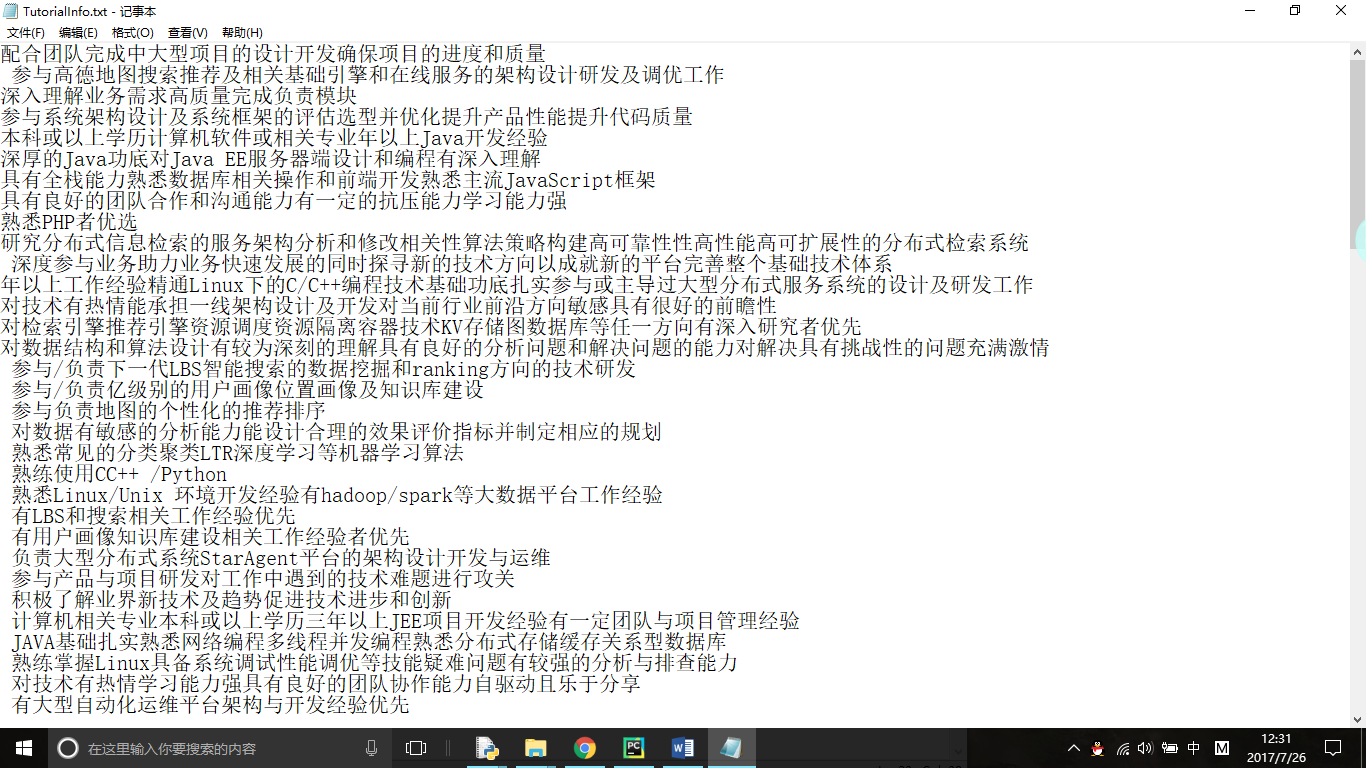 this TXT file is running out, there is something, to prove the function can run, but the data quantity is too little, I use the pycharm view when the first yield
this TXT file is running out, there is something, to prove the function can run, but the data quantity is too little, I use the pycharm view when the first yield 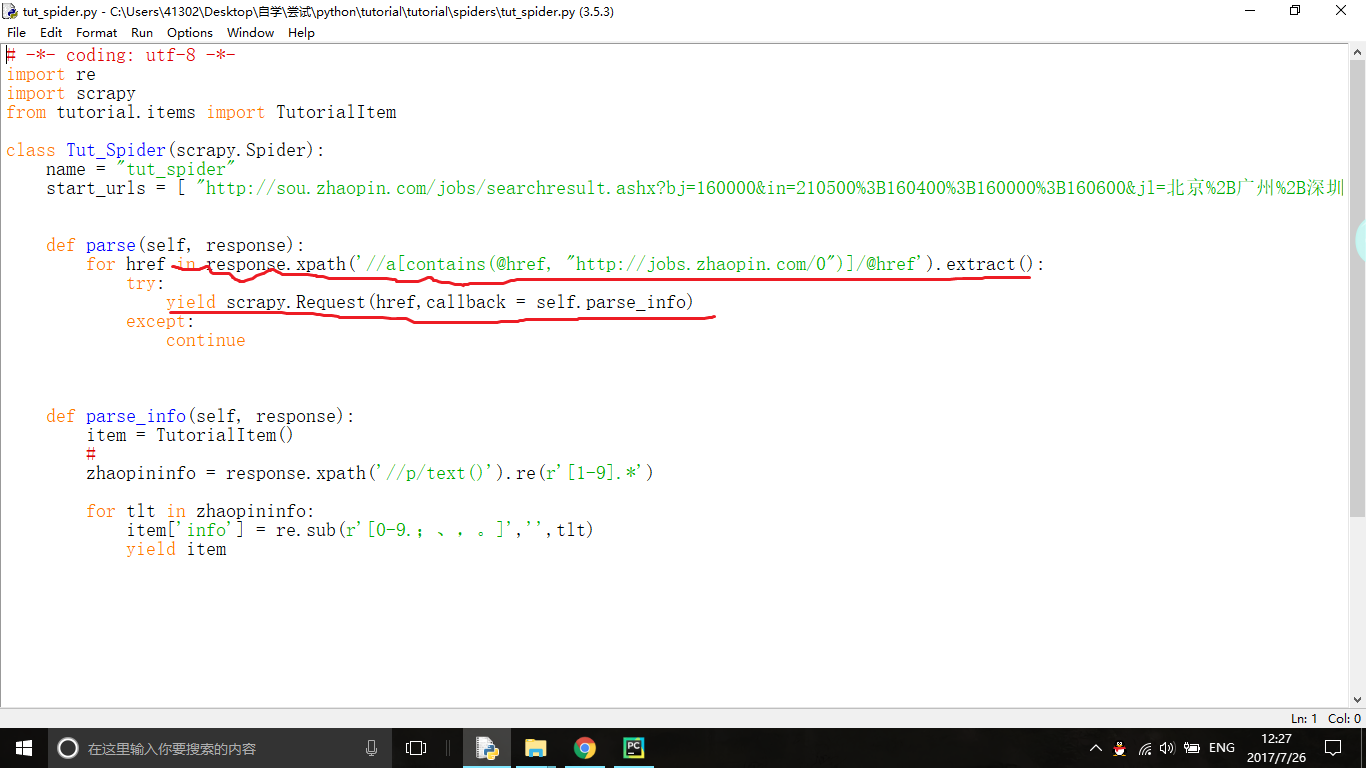 omitted a lot of web sites in these two steps,
omitted a lot of web sites in these two steps,  white coil live sites were omitted, excuse me, is this why? Pray god help!! It'll yield problem, how to change?
white coil live sites were omitted, excuse me, is this why? Pray god help!! It'll yield problem, how to change?CodePudding user response:
No one
CodePudding user response:
Yes, here, here