I am attempting to use REGEX to extract connection strings from blocks of text in a pandas dataframe.
My REGEX works on REGEX101.com (see Screenshot below). Link to my saved test here: 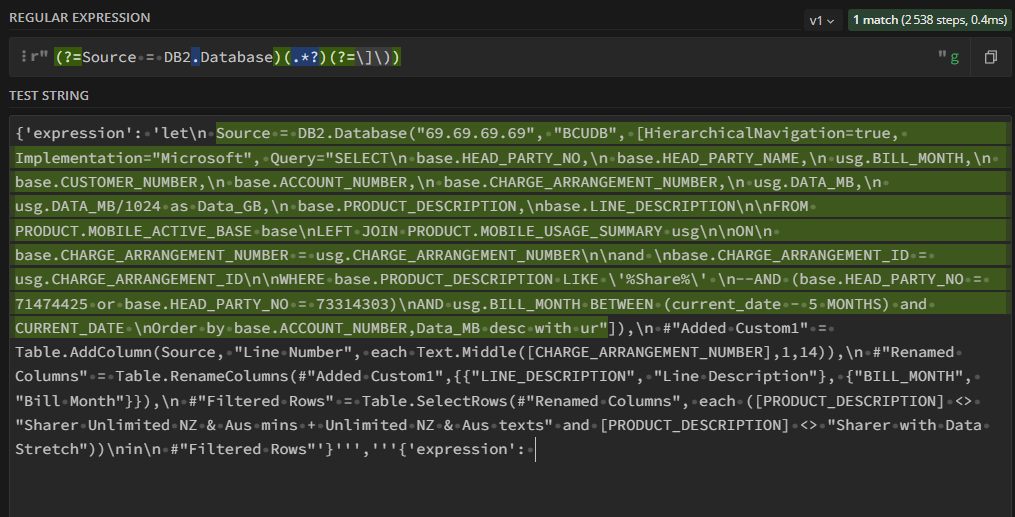
When I try to run the REGEX in a Pandas dataframe, I don’t get any REGEX matches/extracts (but no an error), despite getting matches on REGEX101. Link to my code in a Google Colab notebook: https://colab.research.google.com/drive/1WAMlGkHAOqe38Lzo_K0KHwD_ynVJyIq1?usp=sharing
Therefore the issue appears to be how pandas is interpreting my REGEX
Can anyone identify why I not getting any REGEX matches using pandas?
REGEX Logic My REGEX consists of 3 groups
(?=Source = DB2.Database)(.*?)(?=\]\))
Group 1: (?=Source = DB2.Database) is a “Lookbehind” that looks for the text “Source = DB2.Database” i.e the start of my connection string.
Group 2: (.?)* looks for any characters and acts as a span between the 1st and 3rd group.
Group 3: (?=])) is a look behind assertion that aims to identify the end of the connection string)
Additional tests: When I run a simplified version of the REGEX (DB2.Database) I get the match, as expected. This example is also in the notebook linked above.
My code (same as in linked Colab Notebook)
import pandas as pd
myDF = pd.DataFrame({'conn_str':['''{'expression': 'let\n Source = Snowflake.Databases("whitehouse.australia-east.azure.snowflakecomputing.com","USER"),\n WH_DW_Database = Source{[Name="WHOUSE_DW",Kind="Database"]}[Data],\n DWH_Schema = SPARK_DW_Database{[Name="DWH",Kind="Schema"]}[Data],\n D_ACCOUNT_CURR_View = DWH_Schema{[Name="D_ACCOUNT_CURR",Kind="View"]}[Data],\n #"Filtered Rows" = Table.SelectRows(D_ACCOUNT_CURR_View, each ([PAYMENT_TYPE] = "POSTPAID") and ([ACCOUNT_SEGMENT] <> "Consumer") ),\n #"Removed Other Columns" = Table.SelectColumns(#"Filtered Rows",{"DESCRIPTION", "ACCOUNT_NUMBER"})\nin\n #"Removed Other Columns"'}''','''{'expression': 'let\n Source = DB2.Database("69.699.69.69", "WHUDB", [HierarchicalNavigation=true, Implementation="Microsoft", Query="SELECT\n base.HEAD_PARTY_NO,\n base.HEAD_PARTY_NAME,\n usg.BILL_MONTH,\n base.CUSTOMER_NUMBER,\n base.ACCOUNT_NUMBER,\n base.CHARGE_ARRANGEMENT_NUMBER,\n usg.DATA_MB,\n usg.DATA_MB/1024 as Data_GB,\n base.PRODUCT_DESCRIPTION,\nbase.LINE_DESCRIPTION\n\nFROM PRODUCT.MOBILE_ACTIVE_BASE base\nLEFT JOIN PRODUCT.MOBILE_USAGE_SUMMARY usg\n\nON\n base.CHARGE_ARRANGEMENT_NUMBER = usg.CHARGE_ARRANGEMENT_NUMBER\n\nand \nbase.CHARGE_ARRANGEMENT_ID = usg.CHARGE_ARRANGEMENT_ID\n\nWHERE base.PRODUCT_DESCRIPTION LIKE \'%Share%\' \n--AND (base.HEAD_PARTY_NO = 71474425 or base.HEAD_PARTY_NO = 73314303)\nAND usg.BILL_MONTH BETWEEN (current_date - 5 MONTHS) and CURRENT_DATE \nOrder by base.ACCOUNT_NUMBER,Data_MB desc with ur"]),\n #"Added Custom1" = Table.AddColumn(Source, "Line Number", each Text.Middle([CHARGE_ARRANGEMENT_NUMBER],1,14)),\n #"Renamed Columns" = Table.RenameColumns(#"Added Custom1",{{"LINE_DESCRIPTION", "Line Description"}, {"BILL_MONTH", "Bill Month"}}),\n #"Filtered Rows" = Table.SelectRows(#"Renamed Columns", each ([PRODUCT_DESCRIPTION] <> "Sharer Unlimited NZ & Aus mins Unlimited NZ & Aus texts" and [PRODUCT_DESCRIPTION] <> "Sharer with Data Stretch"))\nin\n #"Filtered Rows"'}''']})
myDF
#why isn't this working?
#this regex works on REGEX 101 : https://regex101.com/r/ILnpS0/1
regex_db =r'(?=Source = DB2.Database)(.*?)(?=\]\))'
myDF['SQLDB connection2'] = myDF['conn_str'].str.extract(regex_db ,expand=True)
myDF
#This is a simplified version of the above REGEX, and works to extracts the text "DB2.Database"
#This works fine
regex_db2 =r'(DB2.Database)'
myDF['SQLDB connection1'] = myDF['conn_str'].str.extract(regex_db2 ,expand=True)
myDF
Any suggestions on what I am doing wrong?
CodePudding user response:
Try running your regex in dot all mode, so that .* will match across newlines:
regex_db = r'(?=Source = DB2.Database)(.*?)(?=\]\))'
myDF["SQLDB connection2"] = myDF["conn_str"].str.extract(regex_db, expand=True, flags=re.S)
myDF