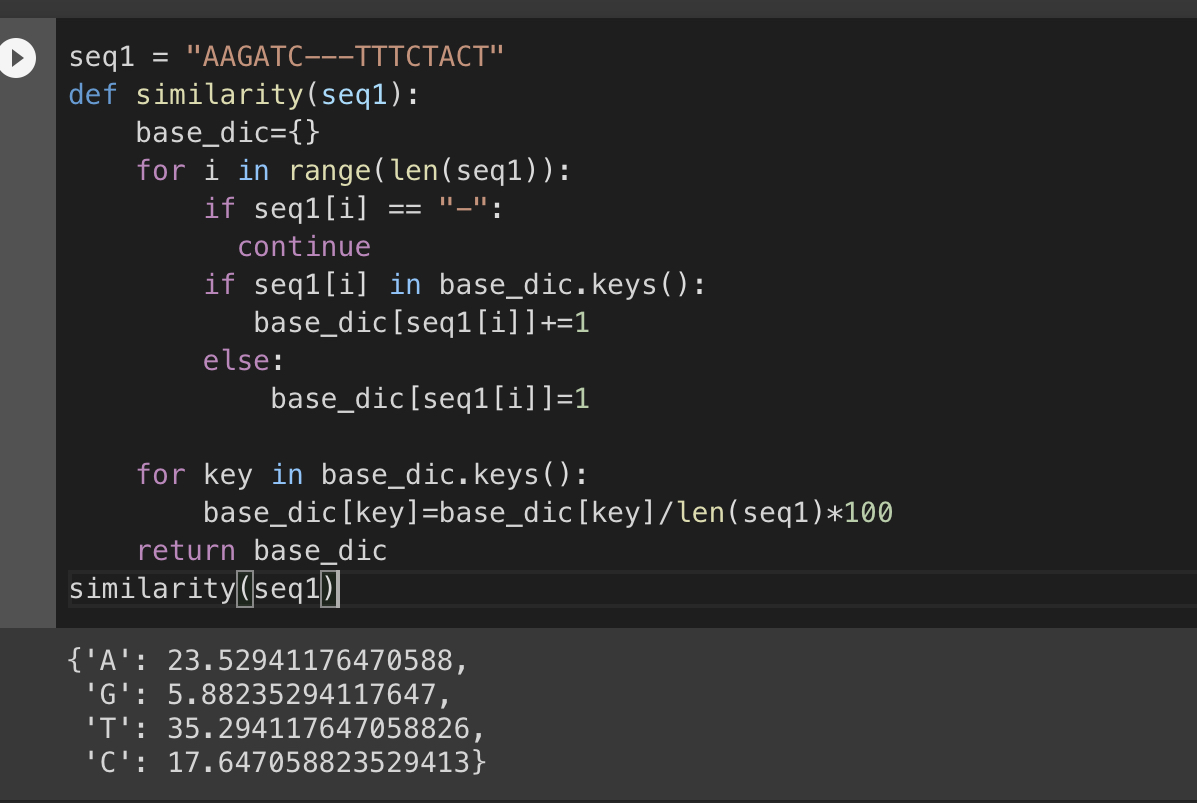
I am new to Python and I need your help in getting the similarity between two sequences. Assuming they are not of the same length and some may have (-) gap symbols.
So here is my code bellow in getting the similarity in only one sequence.
seq1 = "AAAATCCCTAGGGTCAT"
def similarity(seq1):
base_dic={}
for i in range(len(seq1)):
if seq1[i] in base_dic.keys():
base_dic[seq1[i]] =1
else:
base_dic[seq1[i]]=1
for key in base_dic.keys():
base_dic[key]=base_dic[key]/len(seq1)*100
return base_dic
similarity(seq1)
Output:
{'A': 35.294117647058826,
'T': 23.52941176470588,
'C': 23.52941176470588,
'G': 17.647058823529413}
My question is how could I modify this code, so that it can take two sequences at a time and find the similarities?
for ex.
seq1 = "AAAATCCCTAGAAAGGTCAT"
seq2 = “AAGATC---TTTCTACT”
Any ideas? Thanks
i am expecting to get the similarity of A, T, G, C but not -. as they should be counted as unsimilar.
CodePudding user response:
There are 2 parts to this answer.
- Polishes to the code in question.
- Standard algorithm to find how similar 2 strings are.
Part-1: Polishes to your code in the question.
The key takeaways here for you are to make your code more pythonic
from collections import Counter
seq1 = "AAAATCCCTAGGGTCAT"
seq2 = "AAGATC---TTTCTACT"
def get_count(s):
H = defaultdict(int)
n = len(s)
s = [c for c in s if c in "ATCG"]
ctr = Counter(s)
ctr = {k: (v / n) * 100 for k, v in ctr.items()}
return ctr
def calculate_similarity(s1, s2):
result1 = get_count(seq1)
result2 = get_count(seq2)
print(result1)
print(result2)
"""
Add some custom logic here to compute
how similar the strings are (or)
similarity of A, T, C & G
"""
calculate_similarity(seq1, seq2)
Part-2: Standard algorithm to find the similarity b/w to strings is given by Levenshtein distance.
- The Levenshtein distance is a string metric for measuring the difference between two sequences.
- Consider a scenario where you can convert sequence A to sequence B by adding (or) deleting (or) replacing a character. For simplicity, let's assume we have to calculate the number of operations to convert sequence A to B.
- This can be computed by the following logic.
def minDistance(word1: str, word2: str) -> int:
m, n = len(word1), len(word2)
dp = [[0] * (n 1) for _ in range(m 1)]
dp[0][0] = 0
for i in range(m 1):
dp[i][0] = i
for j in range(n 1):
dp[0][j] = j
for i in range(1, m 1):
for j in range(1, n 1):
if word1[i - 1] == word2[j - 1]:
dp[i][j] = dp[i - 1][j - 1]
else:
# dp[i-1][j] -> insert
# dp[i][j-1] -> remove
# dp[i-1][j-1] -> replace
dp[i][j] = min(dp[i - 1][j], dp[i][j - 1], dp[i - 1][j - 1]) 1
return dp[-1][-1]
# The number of operations to convert seq1 to seq2
# This number can help you compare how similar 2 strings are.
result = minDistance(seq1, seq2).
print(result)
References: