I have written algorithm that solves the pluszle game matrix. Input is numpy array.
Now I want to recognize the digits of matrix from screenshot.
Note that you don't the the sums (or whatever they are, I don't know what this game is) here. Which are on the contrary almost black areas
But you can have them with another filter
(hard>120).any(axis=2)
You could merge those filters, obviously
(hard<240).any(axis=2) & (hard>120).any(axis=2)
But that may not be a good idea: after all, it gives you an opportunity to distinguish to different kind of data, why you may want to do.
2- Restrict
Secondly, you know you are looking for digits, so, restrict to digits. By adding config='digits' to your pytesseract args.
pytesseract.image_to_string((hard>240).all(axis=2))
# 'LEVEL10\nNOVEMBER 2022\n\n™\noe\nOs\nfoo)\nso\n‘|\noO\n\n9949 6 2 2 8\n\nN W\nN ©\nOo w\nVon\n ? ah ®)\nas\noOo\n©\n\n \n\x0c'
pytesseract.image_to_string((hard>240).all(axis=2), config='digits')
# '10\n2022\n\n99496228\n\n17\n-\n\n \n\x0c'
3- Don't use image_to_string
Use image_to_data preferably.
It gives you bounding boxes of text.
Or even image_to_boxes which give you digits one by one, with coordinates
Because image_to_string is for when you have a good old linear text in the image. image_to_data or image_to_boxes assumes that text is distributed all around, and give you piece of text with position.
image_to_string on such image may intervert what you would consider the logical order
4- Select areas yourself
Since it is an ad-hoc usage for a specific application, you know where the data are.
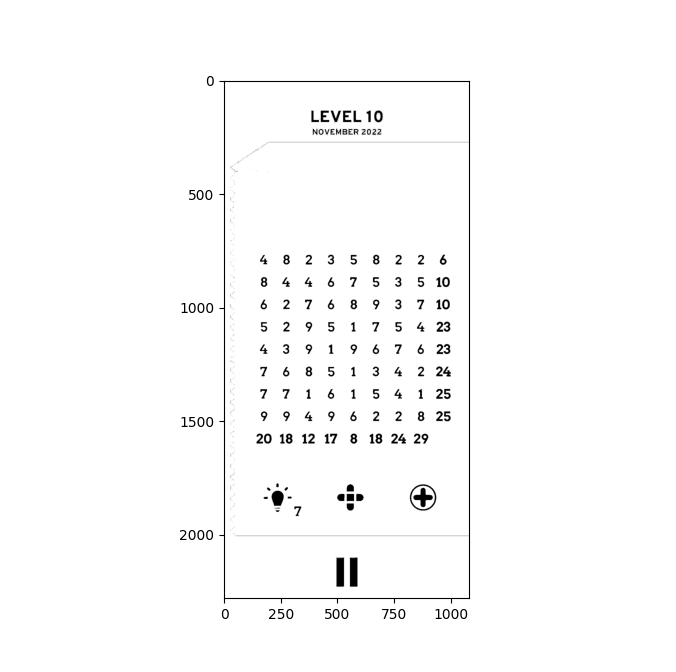
For example, your main matrix seems to be in area
hard[740:1512, 132:910]

See
print(pytesseract.image_to_boxes((hard[740:1512, 132:910]<240).any(axis=2), config='digits'))
Not only it avoids flooding you with irrelevant data. But also, tesseract performs better when called only with an image without other things than what you want to read.
Seems to have almost all your digits here.
5- Don't expect for miracles
Tesseract is one of the best OCR. But OCR are not a sure thing...
See what I get with this code (summarizing what I've said so far)
hard=hard[740:1512, 132:910]
hard=(hard<240).any(axis=2)
boxes=[s.split(' ') for s in pytesseract.image_to_boxes(hard, config='digits').split('\n')[:-1]]
out=255*np.stack([hard, hard, hard], axis=2).astype(np.uint8)
H=len(hard)
for b in boxes:
cv2.putText(out, b[0], (30 int(b[1]), H-int(b[2])), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,0,0), 2)
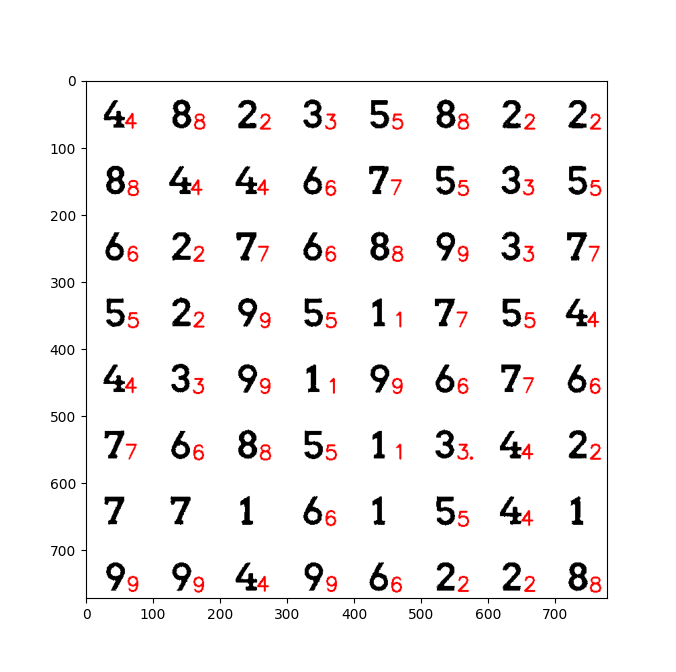
As you can see, result are fairly good. But there are 5 missing numbers. And one 3 was read as "3.".
For this kind of ad-hoc reading of an app, I wouldn't even use tesseract. I am pretty sure that, with trial and errors, you can easily learn to extract each digits box your self (there are linearly spaced in both dimension).
And then, inside each box, well there are only 9 possible values. Should be quite easy, on a generated image, to find some easy criterions, such as the number of white pixels, number of white pixels in top area, ..., that permits a very simple classification
CodePudding user response:
You might want to pre-process the image first. By applying a filter, you can, for example, get the contours of an image.
The basic idea of a filter, is to 'slide' some matrix of values over the image, and multiply every pixel value by the value inside the matrix. This process is called convolution.
Convolution helps out here, because all irrelevant information is discarded, and thus it is made easier for tesseract to 'read' the image.
This might help you out: https://medium.com/swlh/image-processing-with-python-convolutional-filters-and-kernels-b9884d91a8fd