I just started studying Python, requests and BeautifulSoup.
I'm using VSCode and Python version is 3.10.8
I want to get HTML code using a 'taw' tag in google. but I can't get it. the result keeps getting an empty list.
import requests
from bs4 import BeautifulSoup
url = 'https://www.google.com/search?client=safari&rls=en&q=프로그래밍 공부&ie=UTF-8&oe=UTF-8'
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
find = soup.select('#taw')
print(find)
and here's HTML code that I tried to get 'taw' tag
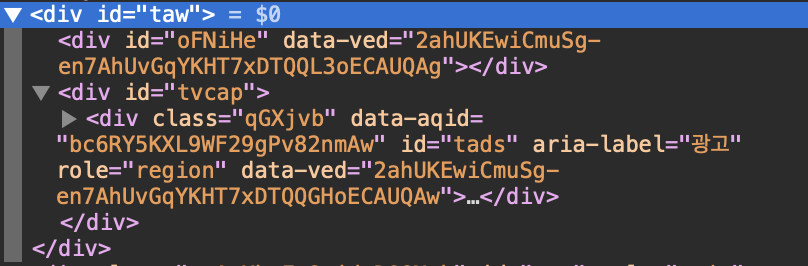
sorry for using image instead of codes.
Taw tag contains Google's ad site and I want to scrap this tag. I tried other CSS properties and tags, but the empty list keeps showing up as a result. I tried soup.find, but I got 'None'.
CodePudding user response:
For various possible reasons, you don't always get the exact same html via python's requests.get as what you see in your browser. Sometimes it's because of blockers or JavaScript loading, but for this specific page and element, it's just that google will format the response a bot differently based on the source of the request. Try adding some headers
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.79 Safari/537.36'
}
url = 'https://www.google.com/search?client=safari&rls=en&q=프로그래밍 공부&ie=UTF-8&oe=UTF-8'
response = requests.get(url, headers=headers)
reqErr = response.raise_for_status() # just a good habit to check
if reqErr: print(f'!"{reqErr}" - while getting ', url)
soup = BeautifulSoup(response.content, 'html.parser')
find = soup.select('#taw')
if not find: ## save html to check [IN AN EDITOR, NOT a browser] if expected elements are missing
hfn = 'x.html'
with open(hfn, 'wb') as f: f.write(response.content)
print(f'saved html to "{hfn}"')
print(find)
The reqErr and if not find.... parts are just to help understand why in case you don't get the expected results. They're helpful for debugging in general for requests bs4 scraping attempts.
The printed output I got with the code above was:
[<div id="taw"><div data-ved="2ahUKEwjvjrj04ev7AhV3LDQIHaXeDCkQL3oECAcQAg" id="oFNiHe"></div><div id="tvcap"></div></div>]