I have a dataframe as follows:
df <- data.frame(code=c("A1","A2","A3","A4","B1","B2","B3","B4"),
pcode = c("el","el","ng","el","ng","el","el","el"),
psaved=c(10,10,10,10,10,10,10,10),
pcost=c(20,20,30,25,34,25,30,20),
scode = c("e1","e2","e2","e2","e2","e2","e3","e3"),
ssaved=c(10,10,10,10,10,10,10,10),
scost=c(20,20,30,25,34,25,30,20),
tcode = c("e2","e3","e1","e1","e3","e3","e2","e1"),
tsaved=c(10,10,10,10,10,10,10,10),
tcost=c(20,20,30,25,34,25,30,20))
I want the dataframe to be widened such that the contents in pcode, scode, and tcode columns become separate columns. And their corresponding saved and cost values are in their respective cells. The result should look something like this:
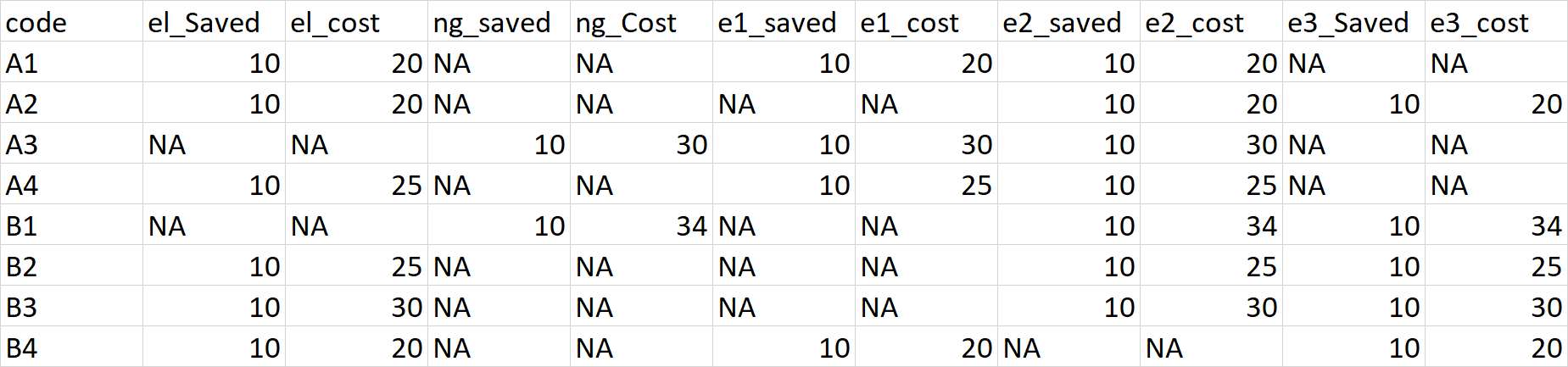
I tried performing pivot_wider to help me get the a wider dataframe with the variables in pcode, scode, tcode to align with their respective cost and save values
CodePudding user response:
One option would be to do this in two steps using pivot_longer first, then do a pivot_wider:
library(tidyr)
library(dplyr)
df %>%
rename(code1 = code) %>%
pivot_longer(-code1,
names_to = c("name", ".value"),
names_pattern = "^(.)(.*)$"
) %>%
select(-name) %>%
pivot_wider(
names_from = code,
values_from = c(saved, cost),
names_glue = c("{code}_{.value}")
) %>%
rename(code = code1)
#> # A tibble: 8 × 11
#> code el_saved e1_sa…¹ e2_sa…² e3_sa…³ ng_sa…⁴ el_cost e1_cost e2_cost e3_cost
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 A1 10 10 10 NA NA 20 20 20 NA
#> 2 A2 10 NA 10 10 NA 20 NA 20 20
#> 3 A3 NA 10 10 NA 10 NA 30 30 NA
#> 4 A4 10 10 10 NA NA 25 25 25 NA
#> 5 B1 NA NA 10 10 10 NA NA 34 34
#> 6 B2 10 NA 10 10 NA 25 NA 25 25
#> 7 B3 10 NA 10 10 NA 30 NA 30 30
#> 8 B4 10 10 NA 10 NA 20 20 NA 20
#> # … with 1 more variable: ng_cost <dbl>, and abbreviated variable names
#> # ¹e1_saved, ²e2_saved, ³e3_saved, ⁴ng_saved