I have a data in excel sheet like as below
Name Segment revenue Product_id Status Order_count days_ago
Dummy High value 1000 P_ABC Yes 2 30 days ago
Dummy High value 1000 P_CDE No 1 20 days ago
Dummy High value 1000 P_EFG Yes 3 10 days ago
Tammy Low value 50 P_ABC No 0 100 days ago
Tammy Low_value 50 P_DCF Yes 1 10 days ago
I would like to do the below steps in order
a) Concat the columns Product_id, Status, Order_count into one column. Use - symbol in between values
b) Group the data based on Name, Segment and revenue
c) Combine multiple rows for same group into one row (in excel).
I tried something like below
df['concat_value'] = df['Product_id'] " - " df['Status'] " - " df['Order_count']
df_group = df.groupby(['Name','Segment','revenue'])
df_nonrepeats = df[df_group['concat_value'].transform('count') == 1]
df_repeats = df[df_group['concat_value'].transform('count') > 1]
But am not able to get the expected output as shown below in the excel sheet.
Can you help me on how can I get the below output in excel sheet?
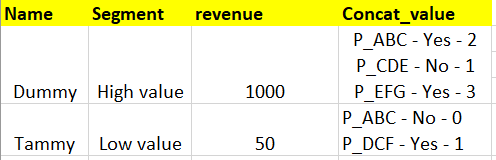
CodePudding user response:
First aggregate values by \n for new lines and then add text_wrap formating for column concat_value - it is mapped to excel columns names by mapping.
Solution working if concat_value is maximal 26. column - mapped to Z excel column name:
import string
df['concat_value'] = df['Product_id'] " - " df['Status'] " - " df['Order_count'] .astype(str)
df = df.groupby(['Name','Segment','revenue'])['concat_value'].agg('\n'.join).reset_index()
mapping = dict(enumerate(string.ascii_uppercase))
print (mapping)
{0: 'A', 1: 'B', 2: 'C', 3: 'D', 4: 'E', 5: 'F', 6: 'G',
7: 'H', 8: 'I', 9: 'J', 10: 'K', 11: 'L', 12: 'M', 13: 'N',
14: 'O', 15: 'P', 16: 'Q', 17: 'R', 18: 'S', 19: 'T',
20: 'U', 21: 'V', 22: 'W', 23: 'X', 24: 'Y', 25: 'Z'}
pos = df.columns.get_loc('concat_value')
print (pos)
3
print (mapping[pos])
D
#https://stackoverflow.com/a/72054821/2901002
with pd.ExcelWriter('file.xlsx', engine='xlsxwriter') as writer:
df.to_excel(writer, sheet_name='Sheet1', index=False)
workbook = writer.book
worksheet = writer.sheets['Sheet1']
cell_format = workbook.add_format({'text_wrap': True})
worksheet.set_column(mapping[pos] ':' mapping[pos], cell_format=cell_format)