Home > other > The crawler xpath is correct but why get get an empty list
The crawler xpath is correct but why get get an empty list
Time:10-13
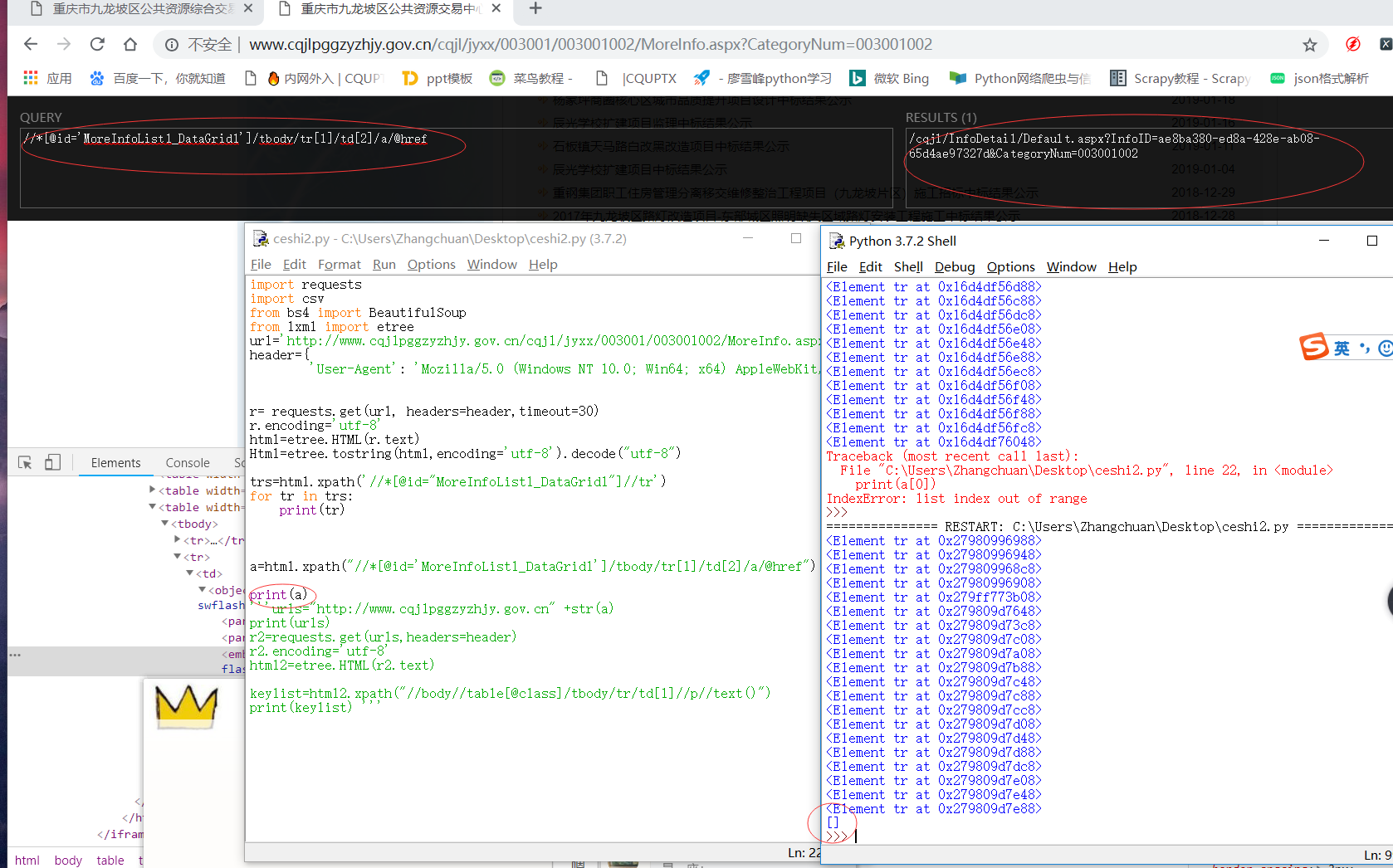
The following picture is the test I wrote: I don't know why a xapth take less than content below returns an empty list But the xpath is right ah,
This is all code, hope bosses correct
import requests The import CSV The from bs4 import BeautifulSoup The from LXML import etree
Url="http://www.cqjlpggzyzhjy.gov.cn/cqjl/jyxx/003001/003001002/MoreInfo.aspx? CategoryNum=003001002 ' The header={ 'the user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; X64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36 '}
Def the main () :
For I in range (1 states) : # post request to modify the form data only need to write to modify part, don't need it all the content in the form Playload={I} '__EVENTARGUMENT: R=requests. Post (url, headers=headers, data=https://bbs.csdn.net/topics/playload, timeout=30) R.e ncoding="utf-8" # or r.c ontent, decode (' utf-8) HTML=etree. HTML (r) HTML=etree. HTML (r.t ext) # xpath to extract all within the tbody tr labels, the tail not text () TRS=HTML. Xpath ('//* [@ id="MoreInfoList1_DataGrid1"]//tr ')
Titles=[] Messages=[] Headers=[' name ', 'time'] Keylists=[] Valuelists=[] # for announcement of the name and date, there is the text () to extract the tags inside the text, and xpath returns is list For the tr in TRS: # all the title of the name of the first Name=tr. Xpath (. '[2]//a///td/text ()') [0] # get all the date of the first Time=((tr) xpath (. '[3]//td/text ()') [0]). The replace (' \ n ', ')). The replace (' \ r ', ') # splicing url, and take the first of all urls Url="http://www.cqjlpggzyzhjy.gov.cn" + tr. Xpath (".//td [2]//a/@ href/text () ") [0] R2=requests. Get (urls, headers=headers) R2. Encoding="utf-8" Html2=etree. HTML (r2. Text)
data=https://bbs.csdn.net/topics/{' the bid-winning notice: the name, 'time: the time } With the open (' the people announcement title ', 'w', encoding="utf-8", newline=' ') as fp: Writer.=the CSV DictWriter (fp, headers) Writer. Writeheader () Writer. Writerows (titles)
# in the table for each element
Keylist=html2. Xpath ("//body/table/@ class/tbody/tr/td [1]//p//text () ") For I in range (6) : Keylists. Append (keylist [I])
# each element in the table corresponding to the value of the Valuelist=html2. Xpath ("//body/table/@ class/tbody/tr/td [2]//p//text () ") For I in range (6) : Valuelists. Append (valuelist [I])