I have a DF similar to the one below:
data = {
'Trade Date': ['2022-12-27', '2022-12-27', '2022-12-27', '2022-12-27', '2022-12-27',
'2022-12-28', '2022-12-28', '2022-12-28', '2022-12-28', '2022-12-28',
'2022-12-29', '2022-12-29', '2022-12-29', '2022-12-29', '2022-12-29'],
'Ticker': ['A', 'B', 'C', 'D', 'E',
'A', 'B', 'C', 'D', 'E',
'A', 'B', 'C', 'D', 'E'],
'Rate': [0.01, 2.82, 1.87, 5.00, 4.92,
0.50, 2.72, 0.99, 8.77, 4.22,
1.01, 3.42, 2.87, 4.50, 25.92]}
df = pd.DataFrame(data)
It contains daily data of stocks traded in Brazilian Exchange -
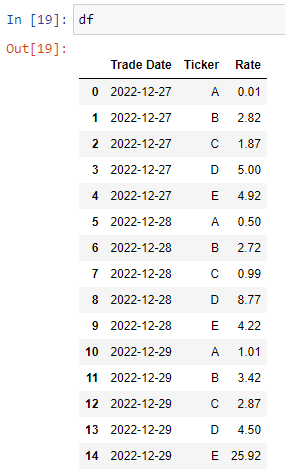
I would like to create a new column shifting 1 day, looking to the columns "Trade Date" and "Ticker" and calculate the daily variation of "Rate". But comparing values between the same ticker and between two dates (dec/29 with dec/28; dec/28 with dec/27; etc).
The output I'd like to see for the Ticker 'A' is given below, however I'd like to do that in the original DF, taking in account all the different Tickers and Trade Dates.
For example: I need to compare the values of 'A' from 2022-12-29 with the values of 'A' from 2022-12-28; The values of 'B' from 2022-12-29 with the values of 'B' from 2022-12-28.
sample = df.loc[df['Ticker'] == 'A'].reset_index(drop=True)
sample['diff'] = sample['Rate'] - sample.shift(1)['Rate']
sample
CodePudding user response:
You can create helper DataFrame with add one day to Trade Date for shift, then add helper column with shifted values:
df['Trade Date'] = pd.to_datetime(df['Trade Date'])
df1 = df.copy()
df1['Trade Date'] = df1['Trade Date'].add(pd.Timedelta('1 day'))
df1 = df.merge(df1, on=['Trade Date','Ticker'], how='left')
df1['diff'] = df1['Rate_x'].sub(df1['Rate_y'])
print (df1)
Trade Date Ticker Rate_x Rate_y diff
0 2022-12-27 A 0.01 NaN NaN
1 2022-12-27 B 2.82 NaN NaN
2 2022-12-27 C 1.87 NaN NaN
3 2022-12-27 D 5.00 NaN NaN
4 2022-12-27 E 4.92 NaN NaN
5 2022-12-28 A 0.50 0.01 0.49
6 2022-12-28 B 2.72 2.82 -0.10
7 2022-12-28 C 0.99 1.87 -0.88
8 2022-12-28 D 8.77 5.00 3.77
9 2022-12-28 E 4.22 4.92 -0.70
10 2022-12-29 A 1.01 0.50 0.51
11 2022-12-29 B 3.42 2.72 0.70
12 2022-12-29 C 2.87 0.99 1.88
13 2022-12-29 D 4.50 8.77 -4.27
14 2022-12-29 E 25.92 4.22 21.70
If all datetimes are consecutive and no missing per groups by tickers is possible also use:
df['diff'] = df.groupby("Ticker")["Rate"].diff()
print (df)
Trade Date Ticker Rate diff
0 2022-12-27 A 0.01 NaN
1 2022-12-27 B 2.82 NaN
2 2022-12-27 C 1.87 NaN
3 2022-12-27 D 5.00 NaN
4 2022-12-27 E 4.92 NaN
5 2022-12-28 A 0.50 0.49
6 2022-12-28 B 2.72 -0.10
7 2022-12-28 C 0.99 -0.88
8 2022-12-28 D 8.77 3.77
9 2022-12-28 E 4.22 -0.70
10 2022-12-29 A 1.01 0.51
11 2022-12-29 B 3.42 0.70
12 2022-12-29 C 2.87 1.88
13 2022-12-29 D 4.50 -4.27
14 2022-12-29 E 25.92 21.70