Please help - I am trying to produce a freq table with row percentages using multiple columns. I know this is simple but I can't seen to find a straightforward code online. Please see example below, where 0 is no and 1 is yes.
df <- structure (list(subject_id = c("191-5467", "191-6784", "191-3457", "191-0987", "191-1245", "191-2365"), fci_1 = c("1","0","0","0","1","0"), fci_2 = c("1","0","1","1","NA","0"), fci_3 = c("1","1","1","1","NA","0"),fci_4 = c("1","0","1","1","1","1")), class = "data.frame", row.names = c (NA, -6L))
Desired table:
| FCI | NO (%) | Yes (%) | NA |
|---|---|---|---|
| fci_1 | 4 (66) | 2 (34) | 0 |
| fci_2 | 2 (33) | 3 (50) | 1 (17) |
| fci_3 | 1 (17) | 4 (66) | 1 (17) |
| fci_4 | 1 (17) | 5 (83) | 0 |
What I've tried
library (table1)
df <- df %>% mutate_if(is.numeric, as.factor)
table1(~ fci_1 fci_2 fci_3 fci_4 | subject_id, data=df)
Which is very similar to what I want but not quite. This shows table per subject_id. 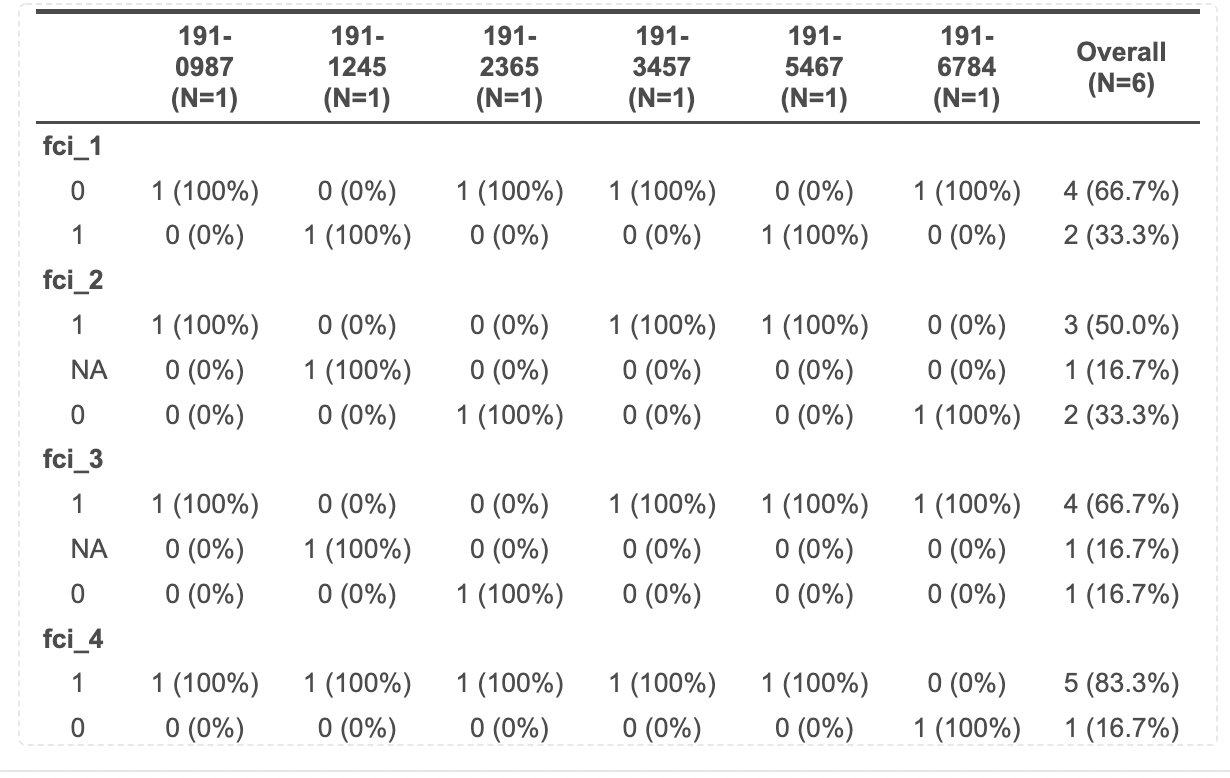
CodePudding user response:
Using dplyr and tidyr you could do:
library(dplyr)
library(tidyr)
df %>%
pivot_longer(-subject_id, names_to = "FCI") |>
group_by(FCI) |>
summarise(n = n(),
No = sum(value == 0),
Yes = sum(value == 1),
"NA" = sum(value == "NA")) |>
mutate(across(c(No, Yes, `NA`), ~ paste0(.x, " (", round(100 * .x / n), ")"))) |>
rename_with(~ paste0(.x, " (%)"), c(No, Yes, `NA`)) |>
select(-n)
#> # A tibble: 4 × 4
#> FCI `No (%)` `Yes (%)` `NA (%)`
#> <chr> <chr> <chr> <chr>
#> 1 fci_1 4 (67) 2 (33) 0 (0)
#> 2 fci_2 2 (33) 3 (50) 1 (17)
#> 3 fci_3 1 (17) 4 (67) 1 (17)
#> 4 fci_4 1 (17) 5 (83) 0 (0)
CodePudding user response:
In base R
tbl1 <- table(stack(df[-1])[2:1])
tbl1[] <- sprintf('%d (%d)', tbl1, round(100 *proportions(tbl1, 1)))
colnames(tbl1) <- c("No (%)", "Yes (%)", "NA (%)")
-output
> tbl1
values
ind No (%) Yes (%) NA (%)
fci_1 4 (67) 2 (33) 0 (0)
fci_2 2 (33) 3 (50) 1 (17)
fci_3 1 (17) 4 (67) 1 (17)
fci_4 1 (17) 5 (83) 0 (0)