I have this df dataset:
df = pd.DataFrame({'train': {'auc': [0.432, 0.543, 0.523],
'logloss': [0.123, 0.234, 0.345]},
'test': {'auc': [0.456, 0.567, 0.678],
'logloss': [0.321, 0.432, 0.543]}})
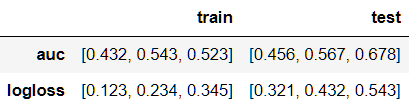
Where I'm trying to transform it into this:
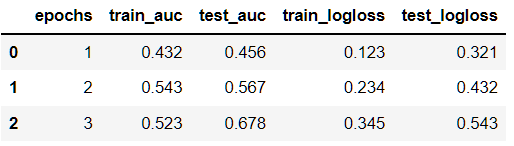
And also considering that:
epochsalways have the same order for every cell, but instead of only 3 epochs, it could reach 1.000 or 10.000.- The column names and axis could change. For example another day the data could have
f1instead oflogloss, orvalinstead oftrain. But no matter the names, indfeach row will always be a metric name, and each column will always be a dataset name. - The number of columns and rows in
dfcould change too. There are some models with 5 datasets, and 7 metrics for example (which would give adfwith 5 columns and 7 rows) - The columname of the output table should be
datasetname_metricname
So I'm trying to build some generic code transformation where at the same time avoiding brute force transformations. Just if it's helpful, the df source is:
df = pd.DataFrame(model_xgb.evals_result())
df.columns = ['train', 'test'] # This is the line that can change (and the metrics inside `model_xgb`)
Where model_xgb = xgboost.XGBClassifier(..), but after using model_xgb.fit(..)
CodePudding user response:
Here's a generic way to get the result you've specified, irrespective of the number of epochs or the number or labels of rows and columns:
df2 = df.stack().apply(pd.Series)
df2.index = ['_'.join(reversed(x)) for x in df2.index]
df2 = df2.T.assign(epochs=range(1, len(df2.columns) 1)).set_index('epochs').reset_index()
Output:
epochs train_auc test_auc train_logloss test_logloss
0 1 0.432 0.456 0.123 0.321
1 2 0.543 0.567 0.234 0.432
2 3 0.523 0.678 0.345 0.543
Explanation:
- Use
stack()to convert the input dataframe to a series (of lists) with a multiindex that matches the desired column sequence in the question - Use
apply(pd.Series)to convert the series of lists to a dataframe with each list converted to a row and with column count equal to the uniform length of the list values in the input series (in other words, equal to the number of epochs) - Create the desired column labels from the latest multiindex rows transformed using
join()with_as a separator, then useTto transpose the dataframe so these index labels (which are the desired column labels) become column labels - Use
assign()to add a column namedepochsenumerating the epochs beginning with1 - Use
set_index()followed byreset_index()to makeepochsthe leftmost column.
CodePudding user response:
Try this:
df = pd.DataFrame({'train': {'auc': [0.432, 0.543, 0.523],
'logloss': [0.123, 0.234, 0.345]},
'test': {'auc': [0.456, 0.567, 0.678],
'logloss': [0.321, 0.432, 0.543]}})
de=df.explode(['train', 'test'])
df_out = de.set_index(de.groupby(level=0).cumcount() 1, append=True).unstack(0)
df_out.columns = df_out.columns.map('_'.join)
df_out = df_out.reset_index().rename(columns={'index':'epochs'})
print(df_out)
Output:
epochs train_auc train_logloss test_auc test_logloss
0 1 0.432 0.123 0.456 0.321
1 2 0.543 0.234 0.567 0.432
2 3 0.523 0.345 0.678 0.543