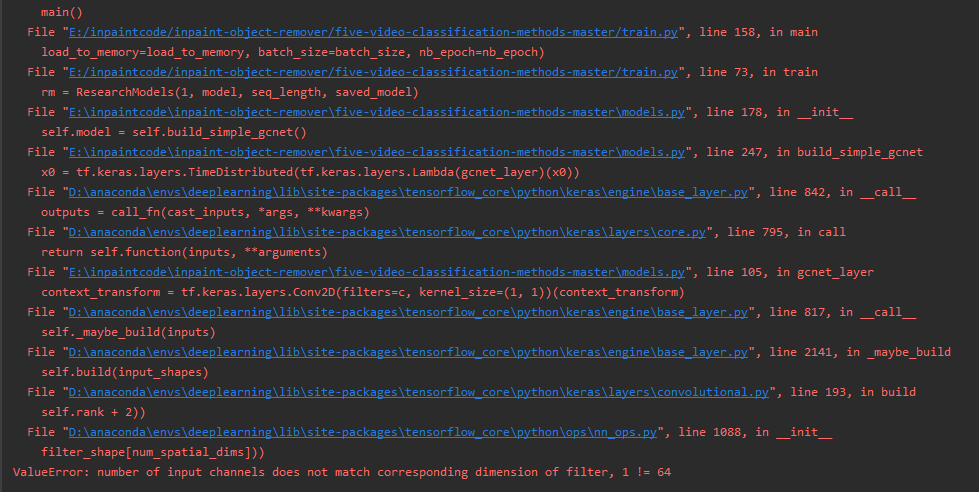
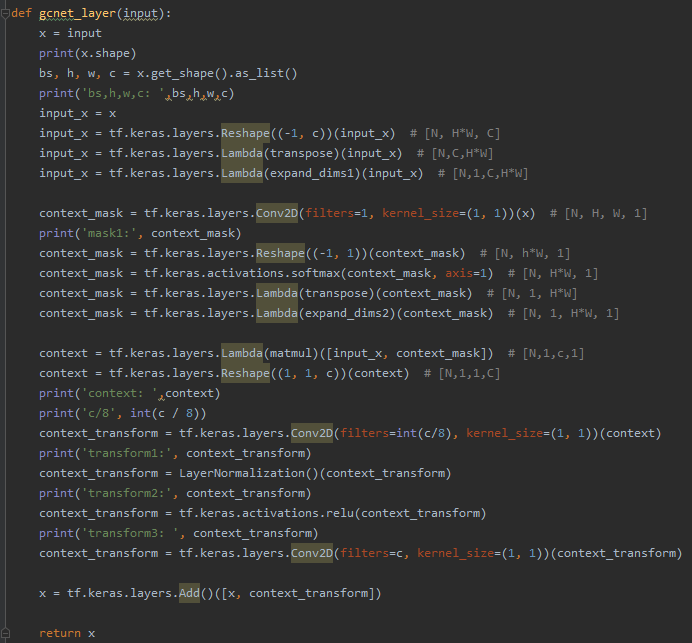
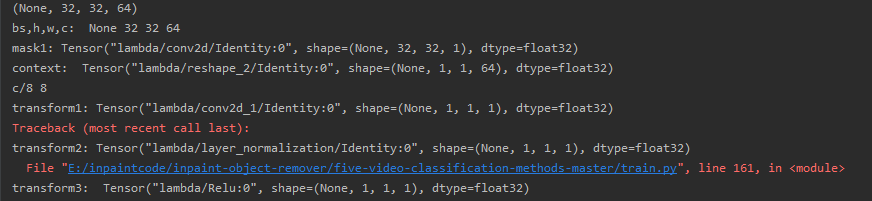
I am doing deepfake video detection, each group of input is 6 pictures, set the batchsize is 32, input shape is (32,6,128,128,3), I am using Timedistrubuted layer handles input in each image, and then I'm going to give each add a layer of attention after image convolution, using gcnet layer, after joining problems appeared in the picture: ValueError: number of input channels does not match corresponding dimension of the filter, 1!=64, then I put gcnet layer layer related to the output out of found is context_transform=tf keras. The layers. The Conv2D (filters=int (c/8), kernel_size=(1, 1)) (context) convolution this time get the characteristics of the figure number is wrong, is 64 c, in theory should be 8 characteristic figure, but only one figure, how to solve this?
Problem picture:
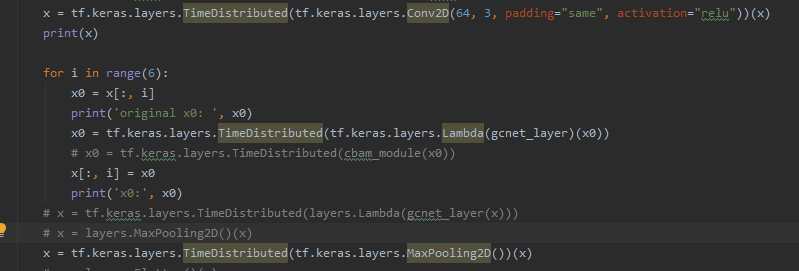
I joined attention layer is so for each picture, don't know what other methods:
Gcnet layer:
Gcnet layer in the output of the print function:
Before I used in image classification gcnet layer, can be normal use,