I am doing web scraping to the real estate portal <www.immobiliare.it>
Specifically I am retrieving some information from the search page, which contains 25 properties per page. I have managed to retrieved almost everything but I am having trouble to retrieve the src of a map image that each property has. This map is after a CSS selector.
The HTML structure is the following:
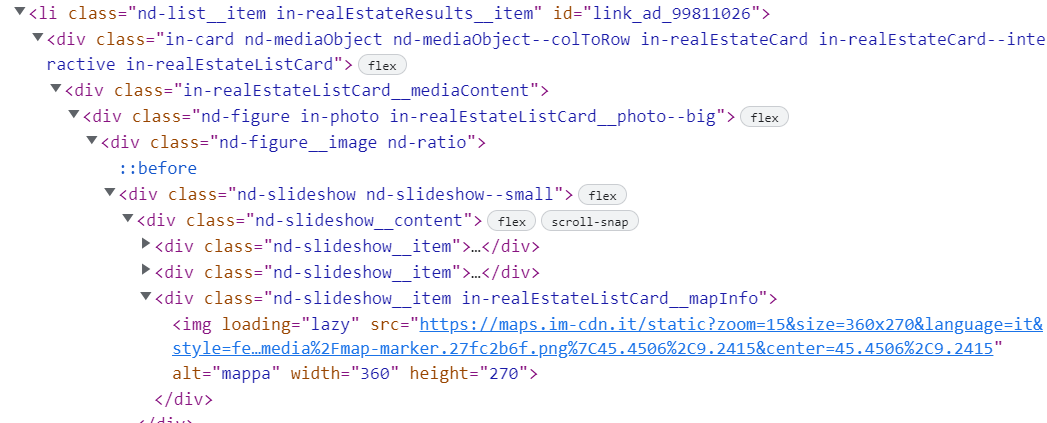
I have been able to get this data with selenium: https://stackoverflow.com/a/75020969/14461986
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
Options = Options()
Options.headless = True
driver = webdriver.Chrome(options=Options, service=Service(ChromeDriverManager().install()))
url = 'https://www.immobiliare.it/vendita-case/milano/forlanini/?criterio=dataModifica&ordine=desc&page=3'
driver.get(url)
soup = BeautifulSoup(driver.page_source)
data = []
# Each property is contained under each li in-realEstateResults__item
for property in soup.select('li.in-realEstateResults__item'):
data.append({
'id': property.get('id'),
'MapUrl': property.select_one('[alt="mappa"]').get('src') if property.select_one('[alt="mappa"]') else None
})
print(data)
However, after the 4th image the MapUrl comes empty. The properties are correcty loaded as I have checked the Ids and also the HTML for the rest of the images is the same but for a reason I do not understand the MapUrl is not retrieved. I would also welcome any advice on how make this script more efficient.
CodePudding user response:
Looks like one of my answers - wouldn't it be great to reference or accept them directly? ;)
However, issue here is lazy loading, so you have to interact with the website and scroll down to force the loading.
You may have to accept / close some popups:
driver.find_element(By.CSS_SELECTOR,'#didomi-notice-agree-button').click()
driver.find_element(By.CSS_SELECTOR,'.nd-dialogFrame__close').click()
driver.find_element(By.CSS_SELECTOR,'section h1').click()
now we can start scrolling (simple but working solution, could be improved):
for i in range(30):
driver.find_element(By.CSS_SELECTOR,'body').send_keys(Keys.PAGE_DOWN)
time.sleep(0.3)
Example
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
url = 'https://www.immobiliare.it/vendita-case/milano/forlanini/?criterio=dataModifica&ordine=desc'
driver.get(url)
driver.find_element(By.CSS_SELECTOR,'#didomi-notice-agree-button').click()
driver.find_element(By.CSS_SELECTOR,'.nd-dialogFrame__close').click()
driver.find_element(By.CSS_SELECTOR,'section h1').click()
for i in range(30):
driver.find_element(By.CSS_SELECTOR,'body').send_keys(Keys.PAGE_DOWN)
time.sleep(0.3)
soup = BeautifulSoup(driver.page_source)
data = []
for e in soup.select('li.in-realEstateResults__item'):
data.append({
'title':e.a.get('title'),
'imgUrls':[i.get('src') for i in e.select('.nd-list__item img')],
'imgMapInfo': e.select_one('[alt="mappa"]').get('src') if e.select_one('[alt="mappa"]') else None
})
data