I'm trying to scrape (in python) the savings interest rate from 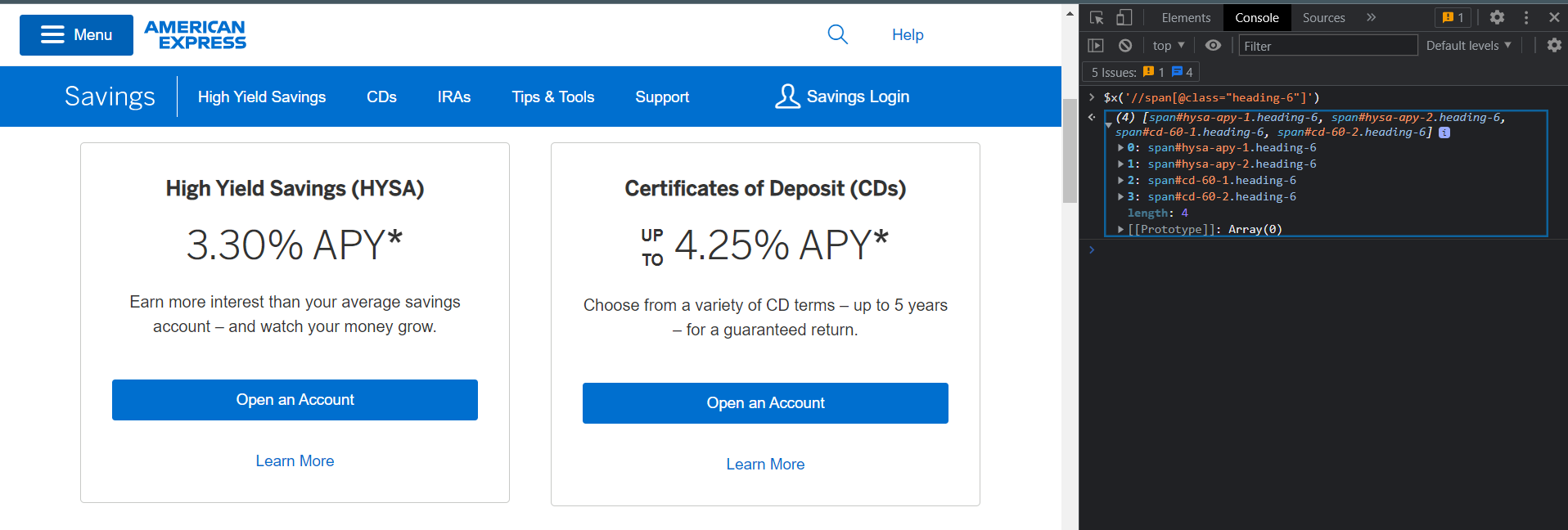
You can also get elements by containing text APY:
'//span[contains(., "APY")]'
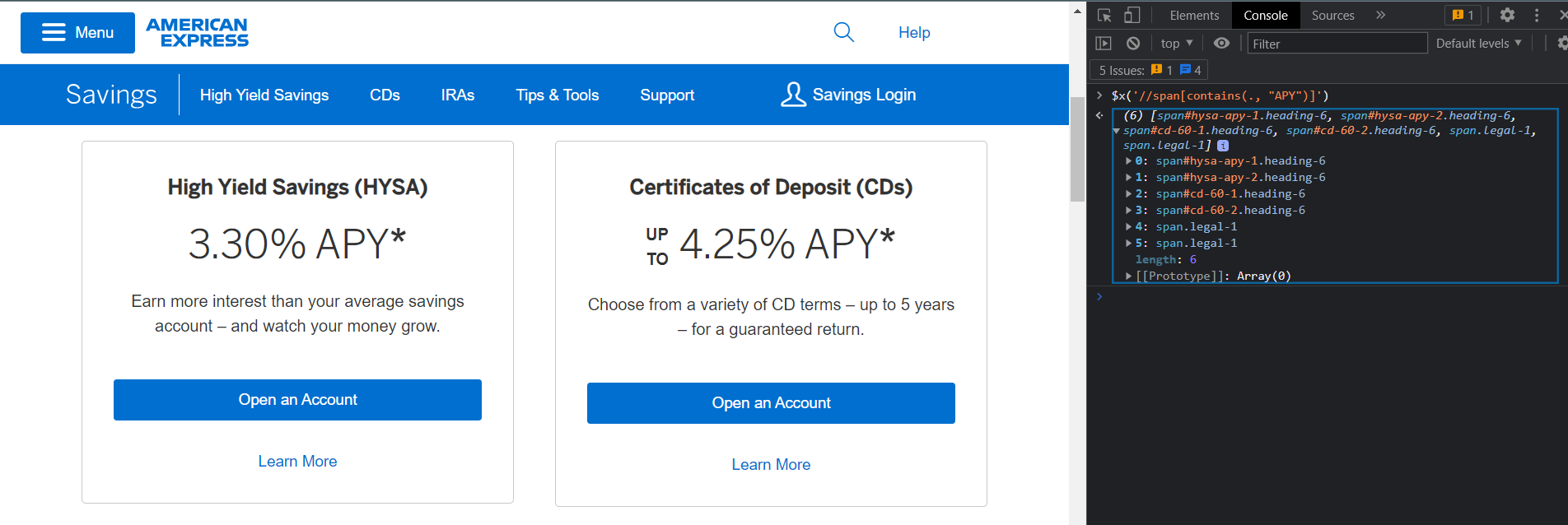 But this selector looks for all span elements in the DOM that contain word
But this selector looks for all span elements in the DOM that contain word APY.
CodePudding user response:
If you find unique id, it is recommended to be priority, like this :find_element(By.ID,'hysa-apy-2') like @John Gordon comment.
But sometimes when the element found, the text not yet load.
Use xpath with add this logic and text()!=""
element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, '//span[@id="hysa-apy-2" and text()!=""]')))
Following import:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC