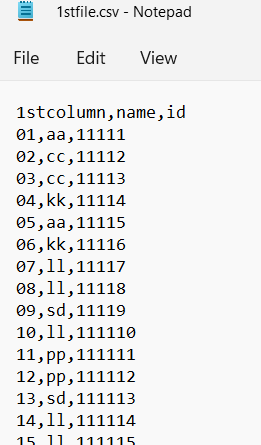
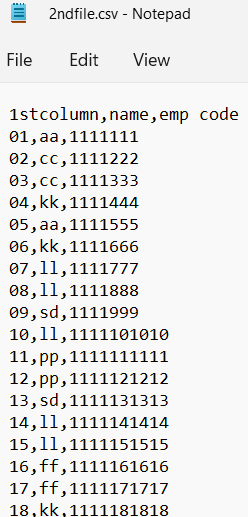
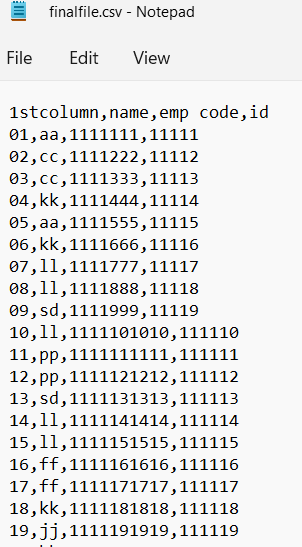
I am using below code to merge two csv files but in both files '1stcolumn' contains numbers start with 01, 02, 03.... till 100 but when is trying to merge two files its merge from 10, 11 12... till 100. why 01 to 09 rows not getting merge. How to merge this full row from 01 to 100 can anyone tell me.
import pandas as pd
data1 = pd.read_csv('1stfile.csv')
data2 = pd.read_csv('2ndfile.csv')
print(data1)
data1['1stcolumn'] = data1['1stcolumn'].astype(str)
data2['1stcolumn'] = data2['1stcolumn'].astype(str)
output1 = pd.merge(data1, data2, on='1stcolumn', how='inner')
print(output1)
output1.to_csv('finalfile.csv', index=False, header=False)
CodePudding user response:
It looks like 1stcolumn was converted to int in one file and str in another. You don't get any error on merge because you are converting the column to string but I think it's too late for that.
Try to do this when the data is loaded and don't let Pandas infer the data type:
data1 = pd.read_csv('1stfile.csv', dtype={'1stcolumn': str})
data2 = pd.read_csv('2ndfile.csv', dtype={'1stcolumn': str})
In your previous code, if you comment out the two lines where you use astype, the merge operation raise an exception like:
ValueError: You are trying to merge on object and int64 columns. If you wish to proceed you should use pd.concat
If your data is '01', '02', '03', Pandas will try to convert as int64 and transform values to 1, 2, 3 but for an unknown reason, it's not the case for the other file.