Say I have table with 3 columns:
col1 col2 col3
1 green 10
1 blue 15
3 red 20
3 yellow 5
4 purple 17
4 black 11
I would like to obtain the max of col3, grouped by col1, while having the value of col2 that belongs to the same row as max(col3):
In other words, the following result set is the desired result:
col1 col2 col3
1 blue 15
3 red 20
4 purple 17
One way I thought of doing this is:
SELECT col1, col3, col2
FROM
(
SELECT ROW() OVER (PARITTION BY col1 ORDER BY col3 DESC) AS rn, col1, col3, col2
GROUP BY col1
) sub
WHERE sub.rn = 1;
But it feels like overkill(if it works), and I'd like to know if there is a much better, more efficient way?
Thanks
CodePudding user response:
First, the best way to get a good answer here is to include some easily composable sample data and DDL. This allows us to actually play around and post a solution you can copy/paste and run locally. Something like this:
DECLARE @t TABLE
(
col1 INT,
col2 VARCHAR(10),
col3 INT
--,INDEX ix_t NONCLUSTERED (Col1 ASC,col3 DESC,col2)
);
INSERT @t(col1,col2,col3) VALUES
(1,'green',10),(1,'blue',15),(3,'red',20),(3,'yellow',5),(4,'purple',17),(4,'black',11);
The solution you posted is fine (though your syntax is wrong) There are a few ways to handle this. The window function solution (ROW_NUMBER() OVER...) is a actually quite elegant and efficient. Another approach would be to use traditional aggregation and a self-join. In either case, proper indexing is key.
Let's compare three solutions: (1) Your ROW_NUMBER solution (2) Aggregation self-join (3) a TOP(1) WITH TIES solution that uses your ROW_NUMBER logic in the ORDER BY clause
(1) ROW_NUMBER solution
SELECT col1, col3, col2
FROM
(
SELECT ROW_NUMBER() OVER (PARTITION BY t.col1 ORDER BY t.col3 DESC) AS rn, col1, col3, col2
FROM @t AS t
) sub
WHERE sub.rn = 1;
(2) Traditional Aggregates
SELECT t.col1, t.col3, t.col2
FROM
(
SELECT t.col1, col3 = MAX(t.col3)
FROM @t AS t
GROUP BY t.col1
) AS s
JOIN @t AS t ON t.col1 = s.col1 AND t.col3 = s.col3;
(3) TOP 1 WITH TIES
SELECT col1, col3, col2
FROM
(
SELECT TOP(1) WITH TIES col1, col3, col2
FROM @t AS t
ORDER BY ROW_NUMBER() OVER (PARTITION BY t.col1 ORDER BY t.col3 DESC)
) sub;
Each query returns:
col1 col3 col2
----------- ----------- ----------
1 15 blue
3 20 red
4 17 purple
The TOP(1) WITH TIES solution is my favorite but it's the least efficient (sadly). To understand which will perform the best let's look at the execution plans with and without the proper index.
No Index plans
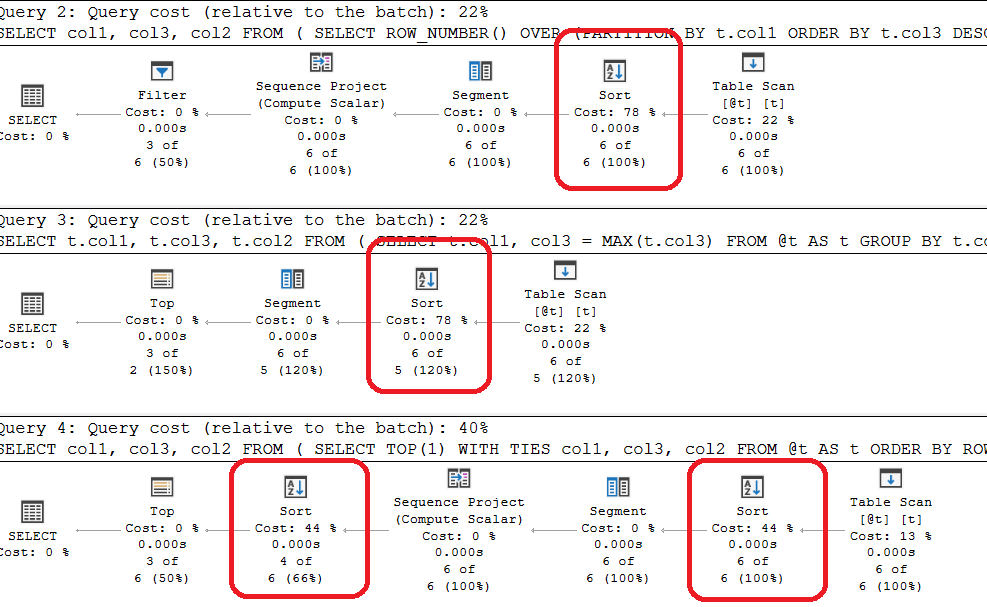
Here the GROUP BY solution is actually a wee-bit better as it does not require a filter or sequence project. The TOP(1) with TIES solution is the worst in that it requires two sorts. Now let's run this with the index on it.
Execution plan with an index

In this case the your solution is the best but not by much. The second index seek is trivial in that it's quickly retrieving the col2 value. The TOP(1) with TIES still gets a sort despite the index. (note that col2 should be an include column but I went with a temp table)
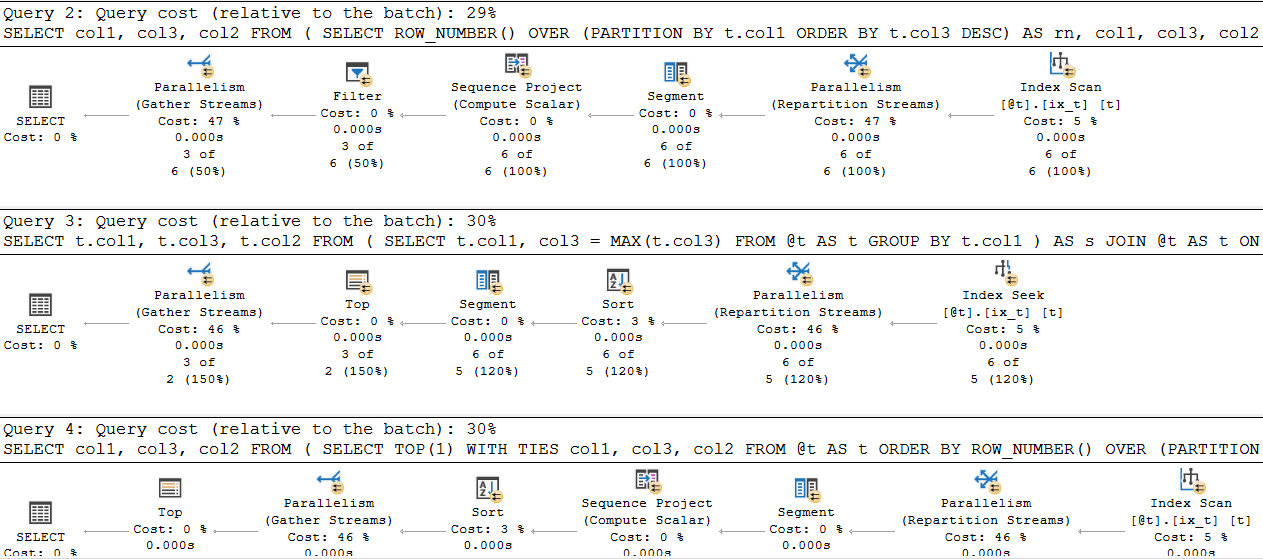
Parallel Execution For testing you can append each query with OPTION (QUERYTRACEON 8649) to see how the query does when ran with multiple CPUs. In this case all three are close but your ROW_NUMBER solution does not get a sort, the other two do.
The lesson here is that you need to try different methods and evaluation the execution plans.
CodePudding user response:
Here's a performance test using the code examples that @Bernie156 was kind enough to put together. Be aware that his "TOP(1) With Ties" code does actually return ties, though.
Here's the test table... 1 million rows total (100K rows, 10 colors)
--===== Create a million row test table with an index.
-- This takes less than a second with or without
-- the index on my box and will produce some "Ties".
DROP TABLE IF EXISTS #TestTable;
GO
CREATE TABLE #TestTable
(
col1 INT
,col2 VARCHAR(10)
,col3 INT
)
;
WITH cteTally AS
(
SELECT TOP 100000
col1 = ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2
)
INSERT INTO #TestTable WITH (TABLOCK)
(col1,col2,col3)
SELECT t.col1
,v.col2
,v.col3
FROM cteTally t
CROSS APPLY
(VALUES
('red' ,CRYPT_GEN_RANDOM(1))
,('orange',CRYPT_GEN_RANDOM(1))
,('yellow',CRYPT_GEN_RANDOM(1))
,('green' ,CRYPT_GEN_RANDOM(1))
,('blue' ,CRYPT_GEN_RANDOM(1))
,('indigo',CRYPT_GEN_RANDOM(1))
,('violet',CRYPT_GEN_RANDOM(1))
,('purple',CRYPT_GEN_RANDOM(1))
,('black' ,CRYPT_GEN_RANDOM(1))
,('white' ,CRYPT_GEN_RANDOM(1))
)v(col2,col3)
;
CREATE NONCLUSTERED INDEX ix_t ON #TestTable (Col1 ASC,col3 DESC,col2)
;
GO
Here's the test code. If you only want one "winner" for each distinct instance of Col1, ROW_NUMBER() work just fine, especially with how simple it is. If you want ties for the top spot of each instance of Col1 to be returned, just replace the ROW_NUMBER() with RANK() and "Bob's your Uncle".
Here's the test code...
GO
-------------------------------------------------------------------------------
PRINT REPLICATE('=',119);
RAISERROR('===== RANK Method ===== (Allows Ties)',0,0) WITH NOWAIT;
DROP TABLE IF EXISTS #Results;
GO
SET STATISTICS TIME,IO ON;
WITH cteRank AS
(
SELECT col1,col2,col3,TheRank = RANK() OVER(PARTITION BY col1 ORDER BY col3 DESC)
FROM #TestTable
)
SELECT col1,col2,col3
INTO #Results
FROM cteRank
WHERE TheRank = 1
;
SET STATISTICS TIME,IO OFF;
GO
-------------------------------------------------------------------------------
PRINT REPLICATE('=',119);
RAISERROR('===== ROW_NUMBER Method ===== (No Ties)',0,0) WITH NOWAIT;
DROP TABLE IF EXISTS #Results;
GO
SET STATISTICS TIME,IO ON;
SELECT col1, col3, col2
INTO #Results
FROM
(
SELECT ROW_NUMBER() OVER (PARTITION BY t.col1 ORDER BY t.col3 DESC) AS rn, col1, col3, col2
FROM #TestTable AS t
) sub
WHERE sub.rn = 1
;
SET STATISTICS TIME,IO OFF;
GO
-------------------------------------------------------------------------------
PRINT REPLICATE('=',119);
RAISERROR('===== Traditional Aggregates ===== (Allows Ties)',0,0) WITH NOWAIT;
DROP TABLE IF EXISTS #Results;
GO
SET STATISTICS TIME,IO ON;
SELECT t.col1, t.col3, t.col2
INTO #Results
FROM
(
SELECT t.col1, col3 = MAX(t.col3)
FROM #TestTable AS t
GROUP BY t.col1
) AS s
JOIN #TestTable AS t ON t.col1 = s.col1 AND t.col3 = s.col3
;
SET STATISTICS TIME,IO OFF;
GO
-------------------------------------------------------------------------------
PRINT REPLICATE('=',119);
RAISERROR('===== TOP 1 WITH TIES ===== (Doesn''t Actually Allow Ties)',0,0) WITH NOWAIT;
DROP TABLE IF EXISTS #Results;
GO
SET STATISTICS TIME,IO ON;
SELECT col1, col3, col2
INTO #Results
FROM
(
SELECT TOP(1) WITH TIES col1, col3, col2
FROM #TestTable AS t
ORDER BY ROW_NUMBER() OVER (PARTITION BY t.col1 ORDER BY t.col3 DESC)
) sub
;
SET STATISTICS TIME,IO OFF;
And, here are the results from my box...
=======================================================================================================================
===== RANK Method ===== (Allows Ties)
Table '#TestTable__________________________________________________________________________________________________________000000000090'.
Scan count 1, logical reads 3891, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 281 ms, elapsed time = 283 ms.
(155903 rows affected)
=======================================================================================================================
===== ROW_NUMBER Method ===== (No Ties)
Table '#TestTable__________________________________________________________________________________________________________000000000090'.
Scan count 1, logical reads 3891, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 172 ms, elapsed time = 160 ms.
(100000 rows affected)
=======================================================================================================================
===== Traditional Aggregates ===== (Allows Ties)
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table '#TestTable__________________________________________________________________________________________________________000000000090'.
Scan count 2, logical reads 7130, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 375 ms, elapsed time = 372 ms.
(155903 rows affected)
=======================================================================================================================
===== TOP 1 WITH TIES ===== (Doesn't Actually Allow Ties)
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Table '#TestTable__________________________________________________________________________________________________________000000000090'.
Scan count 13, logical reads 3985, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1562 ms, elapsed time = 285 ms.
(100000 rows affected)