I am trying to multiply the first columns with the first and with the third columns. Below you can see my data.
df<-data.frame(
Stores=c(10,10,20,0,10),
Value1=c(10,10,0,100,0),
Value2=c(10,10,0,100,0),
Value3=c(10,0,0,0,0),
Value4=c(10,10,0,0,0)
)
df
Now I want to multiply the first column Stores with each subsequent second column or in this case Value2 and Value4.
I tried to do this with mutate but I think that I am not in the right way because, in reality, I need to apply this on large data sets with around 50 columns.
df<-mutate(df,
solved1=Stores*Value2)
So can anybody help me with how to solve this in an automatic way?
CodePudding user response:
Apart from akrun's pure tidyverse solution (which is preferable), we could use dplyover::over() for this kind of operations (disclaimer: I'm, the maintainer, and the package is not on CRAN).
We can create a sequence to loop over, below seq(2, 4, 2) running from 2 to 4 and then we can construct the variable names inside .(), below .("Value{.x}"), so in each iteration we loop over one of the values of our sequence (below: Value2 and Value4).
Finally, we need nice output names. Here we can set the .names argument to "solved{x_idx}" which says "take the string "solved" and append to it the index of the current iteration {x_idx}.
library(dplyr)
library(dplyover) # https://timteafan.github.io/dplyover/
df %>%
mutate(over(seq(2, 4, 2),
~ Stores * .("Value{.x}"),
.names = "solved{x_idx}"
)
)
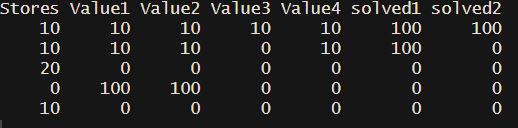
#> Stores Value1 Value2 Value3 Value4 solved1 solved2
#> 1 10 10 10 10 10 100 100
#> 2 10 10 10 0 10 100 100
#> 3 20 0 0 0 0 0 0
#> 4 0 100 100 0 0 0 0
#> 5 10 0 0 0 0 0 0
Created on 2023-01-22 with reprex v2.0.2
CodePudding user response:
We may use across in mutate
library(dplyr)
library(stringr)
df <- df %>%
mutate(across(all_of(names(.)[-1][c(FALSE, TRUE)]), ~ .x * Stores,
.names = "Solved{str_remove(.col, 'Value')}"))
CodePudding user response:
Base R solution, building on @onyambu’s comment:
new <- df[,1] * df[seq(3, ncol(df), by = 2)]
colnames(new) <- paste0("solved", seq_along(new))
df <- cbind(df, new)
df
Stores Value1 Value2 Value3 Value4 solved1 solved2
1 10 10 10 10 10 100 100
2 10 10 10 0 10 100 100
3 20 0 0 0 0 0 0
4 0 100 100 0 0 0 0
5 10 0 0 0 0 0 0
CodePudding user response:
Alternatively, please check
# get the names of the columns to multiply
nam <- names(df)[which(str_detect(names(df),'^Val.*[2|4]$'))]
# use the nam vector with elements as variable names
df %>% mutate(across(nam, ~Stores*.x, .names = 'solved{col}')) %>%
rename_with(., ~ str_replace_all(.x,'Value',''))
Created on 2023-01-22 with reprex v2.0.2
Stores 1 2 3 4 solved2 solved4
1 10 10 10 10 10 100 100
2 10 10 10 0 10 100 100
3 20 0 0 0 0 0 0
4 0 100 100 0 0 0 0
5 10 0 0 0 0 0 0