I want to filter my data. Below you can see how is look like my data.
df<-data.frame(
Description=c("15","11","12","NA","Total","NA","9","18","NA","Total"),
Value=c(158,196,NA,156,140,693,854,NA,904,925))
df
Now I want to filter and assign some text in an additional column. Desired output is need to look like the table shown below. Namely, I want to introduce additional columns with the title Sales.In this column, with the if-else statement, I want to introduce two categorical values. First is Sold and the second is Unsold.The first rows until row 'Total' needs to have the value 'Sold' and other values under this need to have Unsold.
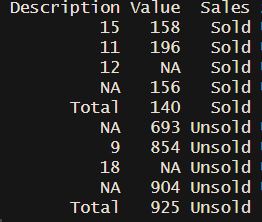
I tried to do this with this command but unfortunately is not work that I expected.
df1$Sales <- ifelse(df$Description==c('Total'),'Sold','Unsold')
So can anybody help me how to solve this?
CodePudding user response:
df$Sales <- ifelse(cumsum(dplyr::lag(df$Description, default = "") == "Total") > 0,
"Unsold",
"Sold")
df
#> Description Value Sales
#> 1 15 158 Sold
#> 2 11 196 Sold
#> 3 12 NA Sold
#> 4 NA 156 Sold
#> 5 Total 140 Sold
#> 6 NA 693 Unsold
#> 7 9 854 Unsold
#> 8 18 NA Unsold
#> 9 NA 904 Unsold
#> 10 Total 925 Unsold
To break down the logic:
dplyr::lagchecks whether the previous entry was"Total". Setting a default of any string other than"Total"prevents creatingNAas the first entry, because that would carry over an unwantedNAinto the next step.cumsumreturns how many times"Total"has been seen as the previous entry.- Checking that the result of
cumsumis greater than 0 turns step 2 into a binary result:"Total"has either been found, or it hasn't. - If
"Total"has been found, it's unsold; otherwise it's sold.
You could also rearrange things:
dplyr::lag(cumsum(df$Description == "Total") < 1, default = TRUE)
gets the same result, with the true & false results in the same order.
CodePudding user response:
If you know there are as many sold as unsold you can use the first solution.
If you want to allow for uneven and unknown numbers of each you could use the second solution.
library(tidyverse)
# FIRST SOLUTION
df |>
mutate(Sales = ifelse(row_number() <= nrow(df) / 2, "Sold", "Unsold"))
# SECOND SOLUTION
df |>
mutate(o = Description == "Total") |>
mutate(Sales = ifelse(row_number() > match(TRUE, o), "Unsold", "Sold")) |>
select(-o)
#> Description Value Sales
#> 1 15 158 Sold
#> 2 11 196 Sold
#> 3 12 NA Sold
#> 4 NA 156 Sold
#> 5 Total 140 Sold
#> 6 NA 693 Unsold
#> 7 9 854 Unsold
#> 8 18 NA Unsold
#> 9 NA 904 Unsold
#> 10 Total 925 Unsold