I have a following dataframe:
data_frame <- structure(list(position = c(10, 15, 10, 10, 25, 19, 25, 15, 20,
31, 22, 20, 10, 19), length = c(21, 15, 19, 10, 27, 19, 25, 31,
34, 31, 26, 27, 10, 19)), class = "data.frame", row.names = c(NA,
-14L))
I want to create the following dataframe from it:
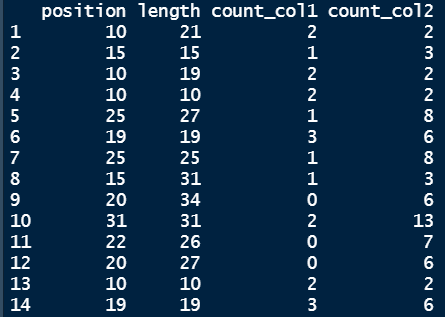
data_frame2 <- structure(list(positionpositions = c(10, 15, 10, 10, 25, 19, 25, 15, 20, 31, 22, 20, 10, 19), lengthlengths = c(21, 15, 19, 10, 27, 19, 25, 31, 34, 31, 26, 27, 10, 19), desired_col1desired_col = c(2, 1, 2, 2, 1, 3, 1, 1, 0, 21, 0, 0, 2, 3), desired_col2 = c(2, 3, 2, 2, 8, 6, 8, 3, 6, 13, 7, 6, 2, 6)), class = "data.frame", row.names = c(NA, -14L))
where:
"desired_col1" - informs of how many "lengths" are equal to the given value in column "position".
desired_col2 - informs of how many "lengths" are equal to or lower than the given value in column "position".
I was trying multiple times, but could not apply the function column-wise.
EDIT: I was able to create the desired column 1 by converting the columns into vectors, using sum within sapply and adding the resulting vector as a new column. Like this:
x <- data_frame$position
y <- data_frame$length
counts <- sapply(x, function(val) sum(val == y))
data_frame$desired <- counts
However, I am still looking for something more straight-forward, a dplyr-based maybe.
Also I am still struggling with desired column 2.
CodePudding user response:
I would get the count of each length element and then join that back to the original data:
library(dplyr)
data_frame %>%
count(length) %>%
rename(position = length) %>%
left_join(data_frame, ., by = "position") %>%
mutate(n = coalesce(n, 0))
# position length n
# 1 10 21 2
# 2 15 15 1
# 3 10 19 2
# 4 10 10 2
# 5 25 27 1
# 6 19 19 3
# 7 25 25 1
# 8 15 31 1
# 9 20 34 0
# 10 31 31 2
# 11 22 26 0
# 12 20 27 0
# 13 10 10 2
# 14 19 19 3
Your sapply solution is quite good for base R, and more straightforward. Do note that "converting the columns into vectors" is skippable, the sapply can be done as a one-liner:
data_frame$desired = sapply(data_frame$position, \(x) sum(x == data_frame$length))
The dplyr solution with the join will be more efficient if your data is large.
Do be careful with your column names. Your two sample data frames and your code are quite inconsistent on length vs lengths and positions vs position.
CodePudding user response:
v <- df$length
df %>%
rowwise() %>%
mutate(
desired_col1 = sum(v == position),
desired_col2 = sum(v <= position)
)
Results
# A tibble: 14 × 4
# Rowwise:
position length desired_col1 desired_col2
<dbl> <dbl> <int> <int>
1 10 21 2 2
2 15 15 1 3
3 10 19 2 2
4 10 10 2 2
5 25 27 1 8
6 19 19 3 6
7 25 25 1 8
8 15 31 1 3
9 20 34 0 6
10 31 31 2 13
11 22 26 0 7
12 20 27 0 6
13 10 10 2 2
14 19 19 3 6
CodePudding user response:
This is the perfect time for some combined mutate and 'lapply' usage!
data_frame %>%
mutate(count_col1 = lapply(position, function(x) sum(x == length)),
count_col2 = lapply(position, function(x) sum(x >= length)))