I have data that are stored in three different data frames with different lengths. Below you can see my data :
df<-data.frame(
retail_seling_price=c(10),
quantity_10=c(1000)
)
df
df1<-data.frame(
retail_seling_price=c(100,200,300),
quantity_18=c(1000,2000,3000)
)
df1
df2<-data.frame(
retail_seling_price=c(100,200,300,400),
quantity_18=c(1000,2000,3000,0)
)
df2
So now I want to merge all these data frames into one data frame, as in the pic shown below.
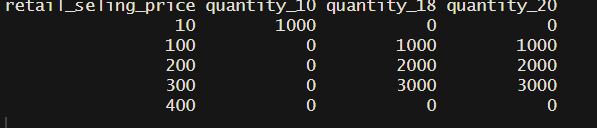
So can anybody help me how to solve this problem ?
CodePudding user response:
Is your df2 supposed to have quantity_20 instead of quantity_18? If so (fixed for below), this is a combination of full_join (for each pair of frames) and Reduce on a list of frames to do the same for an arbitrary number of frames.
library(dplyr)
Reduce(function(a, b) full_join(a, b, by = "retail_seling_price"),
list(df, df1, df2)) %>%
mutate(across(everything(), ~ coalesce(., 0)))
# retail_seling_price quantity_10 quantity_18 quantity_20
# 1 10 1000 0 0
# 2 100 0 1000 1000
# 3 200 0 2000 2000
# 4 300 0 3000 3000
# 5 400 0 0 0
Frankly, we don't need dplyr for this, it's handy to use for fixing all of the NA values introduced by the initial join:
Reduce(function(a, b) full_join(a, b, by = "retail_seling_price"),
list(df, df1, df2))
# retail_seling_price quantity_10 quantity_18 quantity_20
# 1 10 1000 NA NA
# 2 100 NA 1000 1000
# 3 200 NA 2000 2000
# 4 300 NA 3000 3000
# 5 400 NA NA 0
CodePudding user response:
Here is a another dplyr approach using bind_rows:
library(dplyr)
bind_rows(df, df1, df2) %>%
group_by(retail_seling_price) %>%
summarize(across(everything(), ~sum(., na.rm = TRUE)))
retail_seling_price quantity_10 quantity_18 quantity_20
<dbl> <dbl> <dbl> <dbl>
1 10 1000 0 0
2 100 0 1000 1000
3 200 0 2000 2000
4 300 0 3000 3000
5 400 0 0 0