I am a beginner in machine learning in python, and I am working on a binary classification problem. I have implemented a logistic regression model with an average accuracy of around 75%. I have tried numerous ways to improve the accuracy of the model, such as one-hot encoding of categorical variables, scaling of the continuous variables, and I did a grid search to find the best parameters. They all failed to improve the accuracy. So, I looked into unsupervised learning methods in order to improve it.
I tried using KMeans clustering, and I set the n_clusters into 2. I trained the logistic regression model using the X_train and y_train values. After that, I tried testing the model on the training data using cross-validation but I set the cross-validation to be against the labels predicted by the KMeans:
kmeans = KMeans(n_clusters = 2)
kmeans.fit(X_train)
logreg = LogisticRegression().fit(X_train, y_train)
cross_val_score(logreg, X_train, kmeans.labels_, cv = 5)
When using the cross_val_score, the accuracy is averaging over 95%. However, when I use the .score() method:
logreg.score(X_train, kmeans.labels_)
, the score is in the 60s. My questions are:
- What does the significance (or meaning) of the score that is produced when testing the model against the labels predicted by k-means?
- How can I use k-means clustering to improve the accuracy of the model? I tried adding a 'cluster' column that contains the clustering labels to the training data and fit the logistic regression, but it also didn't improve the score.
- Why is there a huge discrepancy between the score when evaluated via cross_val_predict and the .score() method?
CodePudding user response:
I'm having a hard time understanding the context of your problem based on the snippet you provided. Strong work for providing minimal code, but in this case I feel it may have been a bit too minimal. Regardless, I'm going to read between the lines and state some relevent ideas. I'll then attempt to answer your questions more directly.
I am working on a binary classification problem. I have implemented a logistic regression model with an average accuracy of around 75%
This only tells a small amount of the story. knowing what data your classifying and it's general form is pretty vital, and accuracy doesn't tell us a lot about how innaccuracy is distributed through the problem.
Some natural questions:
- Is one class 50% accurate and another class is 100% accurate? are the classes both 75% accurate?
- what is the class balance? (is there more of one class than the other)?
- how much overlap do these classes have?
I recommend profiling your training and testing set, and maybe running your data through TSNE to get an idea of class overlap in your vector space.
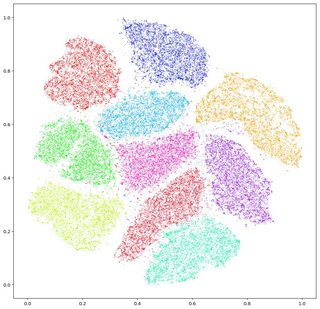
these plots will give you an idea of how much overlap your two classes have. In essence, TSNE maps a high dimensional X to a 2d X while attempting to preserve proximity. You can then plot your flagged Y values as color and the 2d X values as points on a grid to get an idea of how tightly packed your classes are in high dimensional space. In the image above, this is a very easy classification problem as each class exists in it's own island. The more these islands mix together, the harder classification will be.
did a grid search to find the best parameters
hot take, but don't use grid search, random search is better. (source Artificial Intelligence by Jones and Barlett). Grid search repeats too much information, wasting time re-exploring similar parameters.
I tried using KMeans clustering, and I set the n_clusters into 2. I trained the logistic regression model using the X_train and y_train values. After that, I tried testing the model on the training data using cross-validation but I set the cross-validation to be against the labels predicted by the KMeans:
So, to rephrase, you trained your model to predict an output given some input, then tested how it performed predicting the same data and got 75%. This is called training accuracy (as opposed to validation or test accuracy). A low training accuracy is indicative of one of two things:
- there's a lot of overlap between your classes. If this is the case, I would look into feature engineering. Find a vector space which better segregates the two classes.
- there's not a lot of overlap, but the front between the two classes is complex. You need a model with more parameters to segregate your two classes.
model complexity isn't free though. See the curse of dimensionality and overfitting.
ok, answering more directly
these accuracy scores mean your model isn't complex enough to learn the problem, or there's too much overlap between the two classes to see a better accuracy.
I wouldn't use k-means clustering to try to improve this. k-means attempts to find cluster information based on location in a vector space, but you already have flagged data
y_trainso you already know which clusters data should belong in. Try modifyingX_trainin some way to get better segregation, or try a more complex model. you can use things likek-meansorTSNEto check your transformedX_trainfor better segregation, but I wouldn't use them directly. Obligatory reminder that you need to test and validate with holdout data. see another answer I provided for more info.I'd need more code to figure that one out.
p.s. welcome to stack overflow! Keep at it.