I have a csv (see image below) with the first 2 rows as the column headers and I need the first header row to be the header and second header row to be transposed for every row.

I tried transposing and using the pivot functions but those didn't work. I also tried the pivot_table but that wasn't working either.
The expected output is:
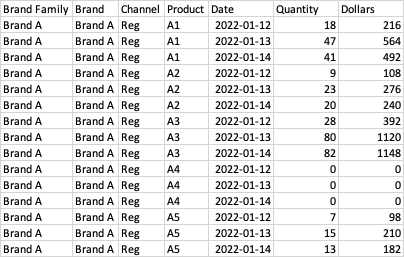
CodePudding user response:
You have to mix melt to flat your dataframe then pivot_table to reshape it according your expected output:
>>> (df.melt(var_name=['Variable', 'Date'], value_name='Value', ignore_index=False)
.pivot_table(index=df.index.names ['Date'], columns='Variable', values='Value')
.reset_index().rename_axis(columns=None))
Brand Family Brand Channel Product Date Dollars Quantity
0 A A Reg A1 2022-01-12 4 1
1 A A Reg A1 2022-01-13 5 2
2 A A Reg A1 2022-01-14 6 3
3 A A Reg A2 2022-01-12 14 11
4 A A Reg A2 2022-01-13 15 12
5 A A Reg A2 2022-01-14 16 13
Input:
>>> df
Quantity Dollars
2022-01-12 2022-01-13 2022-01-14 2022-01-12 2022-01-13 2022-01-14
Brand Family Brand Channel Product
A A Reg A1 1 2 3 4 5 6
A2 11 12 13 14 15 16
CodePudding user response:
I just assumed your CSV file is like the one I have inline in my code.
Solution
First, read the file and ignore the headers.
import io
import pandas as pd
import numpy as np
csv_file = io.StringIO('''\
,,,,Quantity,Quantity,Quantity,Dollars,Dollars,Dollars
Brand Family,Brand,Channel,Product,2022-01-12,2022-01-13,2022-01-14,2022-01-12,2022-01-13,2022-01-14
Brand A,Brand A,Reg,A1,18,47,41,216,164,492
Brand A,Brand A,Reg,A2,9,23,20,108,276,240
Brand A,Brand A,Reg,A3,28,80,82,392,1120,1148
Brand A,Brand A,Reg,A4,,,,,,
Brand A,Brand A,Reg,A5,7,15,13,98,210,182\
''')
df = pd.read_csv(csv_file, header=None).replace(np.nan, 0)
print(df)
0 1 2 3 4 5 6 7 8 9
0 0 0 0 0 Quantity Quantity Quantity Dollars Dollars Dollars
1 Brand Family Brand Channel Product 2022-01-12 2022-01-13 2022-01-14 2022-01-12 2022-01-13 2022-01-14
2 Brand A Brand A Reg A1 18 47 41 216 164 492
3 Brand A Brand A Reg A2 9 23 20 108 276 240
4 Brand A Brand A Reg A3 28 80 82 392 1120 1148
5 Brand A Brand A Reg A4 0 0 0 0 0 0
6 Brand A Brand A Reg A5 7 15 13 98 210 182
And let's divide it into two pieces, the left part
left = df.iloc[2:, :4].set_axis(df.iloc[1, :4], axis='columns')
print(left)
1 Brand Family Brand Channel Product
2 Brand A Brand A Reg A1
3 Brand A Brand A Reg A2
4 Brand A Brand A Reg A3
5 Brand A Brand A Reg A4
6 Brand A Brand A Reg A5
and the right part.
right = df.iloc[:, 4:].T
print(right)
0 1 2 3 4 5 6
4 Quantity 2022-01-12 18 9 28 0 7
5 Quantity 2022-01-13 47 23 80 0 15
6 Quantity 2022-01-14 41 20 82 0 13
7 Dollars 2022-01-12 216 108 392 0 98
8 Dollars 2022-01-13 164 276 1120 0 210
9 Dollars 2022-01-14 492 240 1148 0 182
Now, pivot the right part
pivoted = right.pivot(index=0, columns=[1]).T.reset_index(level=1, names=[0, 'Date'])
print(pivoted)
and note the index is consistent with the left part's.
0 Date Dollars Quantity
2 2022-01-12 216 18
2 2022-01-13 164 47
2 2022-01-14 492 41
3 2022-01-12 108 9
3 2022-01-13 276 23
3 2022-01-14 240 20
4 2022-01-12 392 28
4 2022-01-13 1120 80
4 2022-01-14 1148 82
5 2022-01-12 0 0
5 2022-01-13 0 0
5 2022-01-14 0 0
6 2022-01-12 98 7
6 2022-01-13 210 15
6 2022-01-14 182 13
Finally, join them by the common index.
df = left.join(pivoted).reset_index(drop=True)
print(df)
Brand Family Brand Channel Product Date Dollars Quantity
0 Brand A Brand A Reg A1 2022-01-12 216 18
1 Brand A Brand A Reg A1 2022-01-13 164 47
2 Brand A Brand A Reg A1 2022-01-14 492 41
3 Brand A Brand A Reg A2 2022-01-12 108 9
4 Brand A Brand A Reg A2 2022-01-13 276 23
5 Brand A Brand A Reg A2 2022-01-14 240 20
6 Brand A Brand A Reg A3 2022-01-12 392 28
7 Brand A Brand A Reg A3 2022-01-13 1120 80
8 Brand A Brand A Reg A3 2022-01-14 1148 82
9 Brand A Brand A Reg A4 2022-01-12 0 0
10 Brand A Brand A Reg A4 2022-01-13 0 0
11 Brand A Brand A Reg A4 2022-01-14 0 0
12 Brand A Brand A Reg A5 2022-01-12 98 7
13 Brand A Brand A Reg A5 2022-01-13 210 15
14 Brand A Brand A Reg A5 2022-01-14 182 13
CodePudding user response:
You could also use:
df1 = pd.read_csv('path/file.csv', header=[0, 1], index_col=[0,1,2,3])
df1.stack().reset_index()
Brand Family Brand Channel Product Date Quantity Dollars
0 A A Reg A1 2022-01-12 1 4
1 A A Reg A1 2022-01-13 2 5
2 A A Reg A1 2022-01-14 3 6
3 A A Reg A2 2022-01-12 11 14
4 A A Reg A2 2022-01-13 12 15
5 A A Reg A2 2022-01-14 13 16
where df1 is your data