I'm using Selenium and Python
Hi guys, I'm doing webscrapping on the latamairlines webpage when i try to find elements inside a webelement the scrapper throws me all the elements and not only the elements within that webelement
In this case I'm taking each month in the "a" variable, and I select only the three months that actually appear on the image, though "a" has 5 elements, the 2 months before and after the 3 on the image, BTW when I print text of the 5 elements it tehre are two nulls and 3 texts that are the months that appear on the image. After selecting only the webelement from which I want to scrap their webelements that would be the days, in this case the first month there I webscrap the webelements within, but it ends up throwing me every webelement with that tabindex (I also tried with ID, and others) 153 elements, when I only want the 31 elements inside that "a" or block.
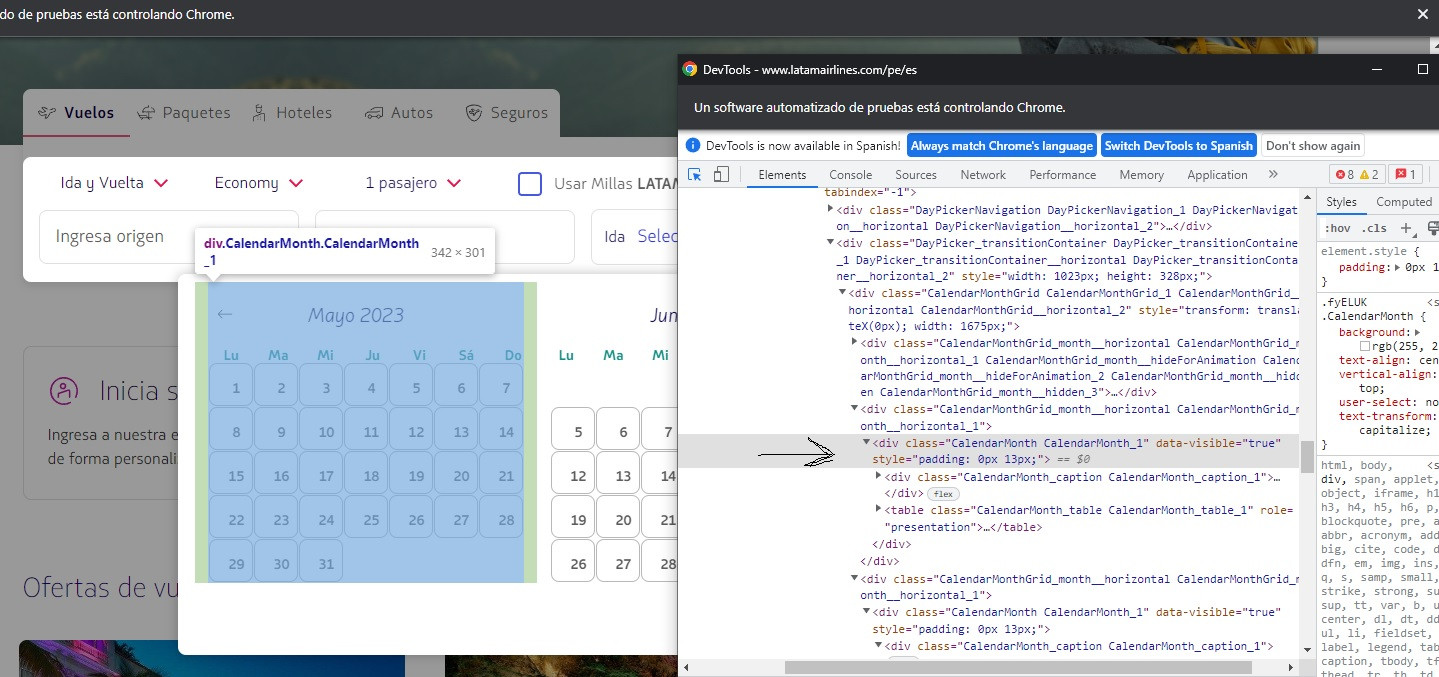
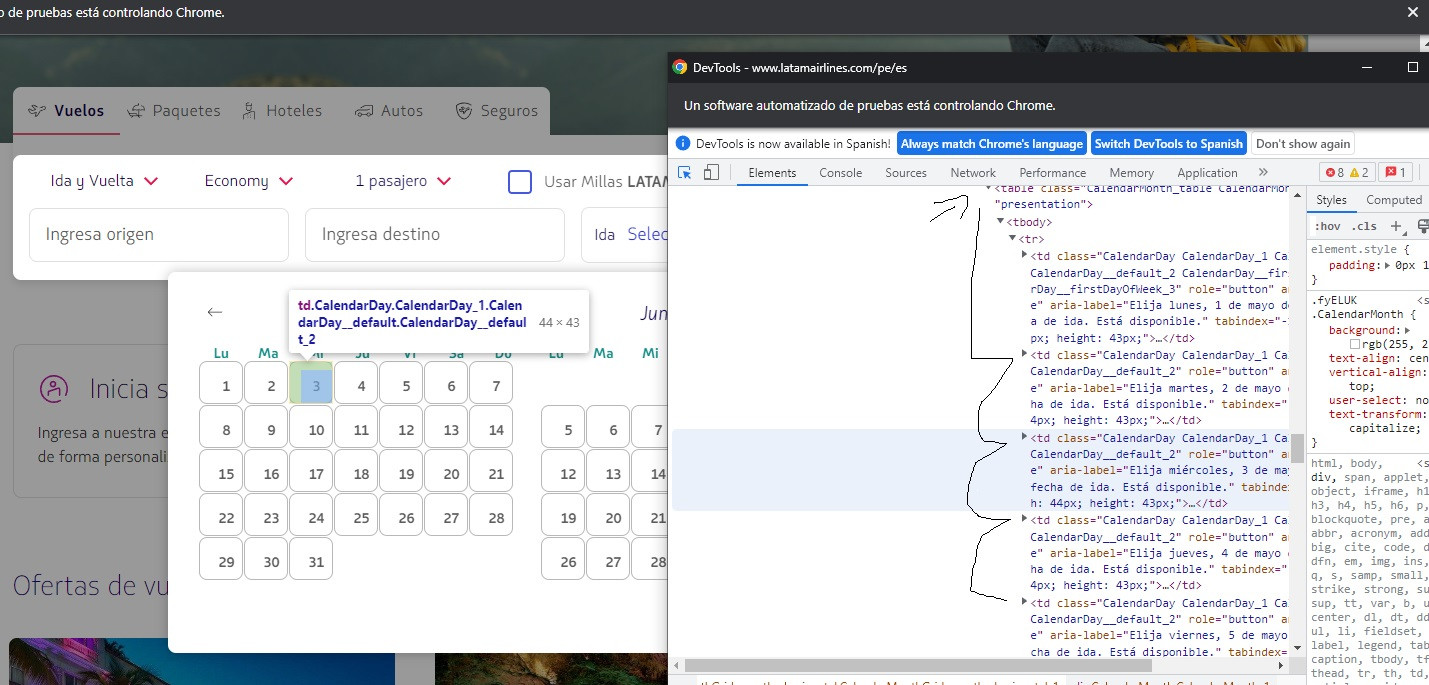
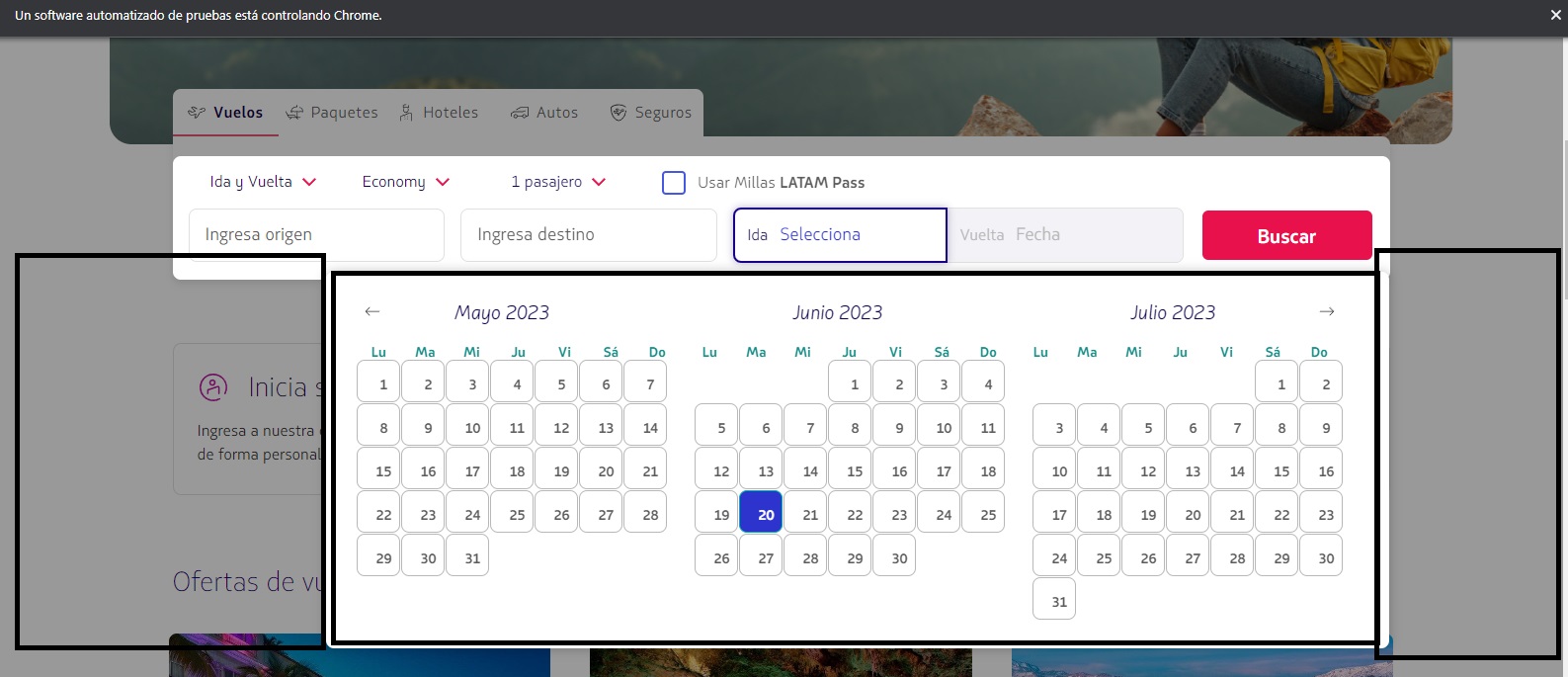
a = driver.find_elements(By.XPATH, "//table[@class='CalendarMonth_table CalendarMonth_table_1']")
len(a)
5
a = a[1:4]
[<selenium.webdriver.remote.webelement.WebElement (session="9f1eb3d17f3d7e200004db0994fc2ef0", element="0676bf58-035b-4d63-b8d0-61645432d571")>,
<selenium.webdriver.remote.webelement.WebElement (session="9f1eb3d17f3d7e200004db0994fc2ef0", element="55618f44-965b-4f70-8bb5-53a7976f674a")>,
<selenium.webdriver.remote.webelement.WebElement (session="9f1eb3d17f3d7e200004db0994fc2ef0", element="cfd6186a-1301-4b09-a595-91ede08f6387")>]
a = a[0]
b = a.find_elements(By.XPATH, "//td[@tabindex='-1']")
len(b)
153
len(b) should be only 31 elements and not 153.
As you see above, I tried to find the Element/block from which I want to extract the elements/days, and it didn't work
CodePudding user response:
When using XPath to find elements (b) from elements (a), you need to add a "." at the start of the XPath,
b = a.find_elements(By.XPATH, ".//td[@tabindex='-1']")
^ dot goes here
That tells the XPath to start searching from that element rather than from the top of the DOM.