The import bs4
The import re
Def open_url (url) :
Headers={' the user-agent ':' Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE (2) X 1.0 'MetaSr}
Res=requests. Get (url, headers=headers)
Return res
Def find_movies (res) :
Soup=bs4. BeautifulSoup (res) text, '. The HTML parser)
# movie
Movies=[]
The targets=soup. Find_all (" div ", class_="hd")
For each in the targets:
Movies. Append (each. A.s pan. Text)
# score
Ranks=[]
The targets=soup. Find_all (' span, class_='rating_num')
For each in the targets:
Ranks. Append (' score: % s' % each. The text)
# information
Messages=[]
The targets=soup. Find_all (' div 'class_=' bd ')
For each in the targets:
Try:
Messages. Append (each. P.t ext split (' \ n ') [1]. Strip () + each. P.t ext split (' \ n ') [2]. Strip ())
Except:
The continue
Result=[]
Length=len (movies)
For I in range (length) :
Result. Append (movies [I] + ranks messages [I] + [I] + '/n')
Return the result
Def the main () :
The host='https://movie.douban.com/top250'
Res=open_url (host)
The depth=10
Result=[]
For I in range (the depth) :
Url=host + '? 25 * start="+ STR (I) + '& amp; The filter='
Res=open_url (url)
Result. The extend (find_movies (res))
With the open (' doubaner. TXT ', 'w', encoding="utf-8") as f:
For each result in:
F.w rite (each)
F. lose ()
If __name__=="__main__ ':
main()
CodePudding user response:
You are not, as long as the film scores and information, it is normalCodePudding user response:
Why my result is only a headerCodePudding user response:
Use your code to run, return the douban. TXT messages have ah,,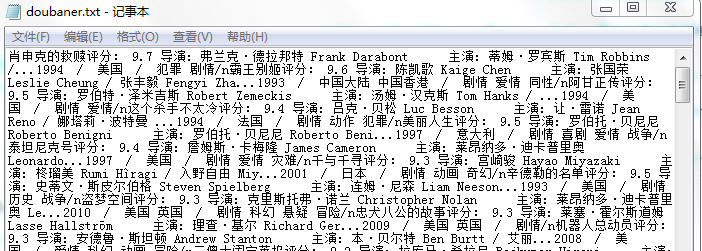
CodePudding user response:
What also have no feedback after runningCodePudding user response:
Your res. Text preserved see content rightCodePudding user response:
Try to use simplified - scrapy by the library, he give you see, the need to install the PIP install simplified - scrapythe from simplified_scrapy. Simplified_doc import SimplifiedDoc
Def test (HTML) :
Doc=SimplifiedDoc (HTML)
LST=doc. GetElements (' div 'value="https://bbs.csdn.net/topics/info")
Movies=[]
For l in LST:
The line=l.i nnerHtml
Title=doc. GetElementByTag (' a ', line)
Obj={}
If (title) :
Obj [' href ']=title. Href
Obj (" title ")=title. The text
Star=doc. GetElementByClass (' rating_num, line)
If (star) :
Obj [' star ']=star. Text
Info=doc. GetElementsByTag (' p ', line)
If (info) :
Obj [' info ']='
For I in info:
Obj +=[' info '] i.t ext
Movies. Append (obj)
Return movies
CodePudding user response:
I didn't run,But see you w to write files in the for loop, so there must be a data covered