The from fake_useragent import UserAgent
The import CSV
The import re
The import time
Import the random
The class CFP2_spider (object) :
Def __init__ (self) :
Self. First_url='https://www.springer.com/journal/11263/updates'
Self. Second_url='https://www.springer.com/journal'
The self. The headers={' the user-agent ':' Mozilla/5.0 (Windows NT 10.0; Win64; X64; The rv: 76.0) Gecko/20100101 Firefox/76.0 '}
Self. Regex_first='& lt; A href="HTTP://https://bbs.csdn.net/topics//journal/11263/updates/. *?) "'
Self. Regex_title='& lt; H1 & gt; (. *?) Self. Regex_submissiontime='& lt; p> . *? Submission deadline: & lt;/strong> (. *?) |
. *? (Submission deadline: [^ & lt;/strong>] . *?)
|Self. Regex_decisiontime='& lt; [a zA - Z] & gt; (final. * decision:. *?) (final decision by. *?) '
Self. Regex_manuscript_submission='& lt; [a zA - Z] & gt; (final yoshinori miura. *? :. *?) Self. Regex_submission_email='([a zA - z] + ://VISI [^ \ s] *? .com) '
# get secondary page URL function
Def getres (self, url) :
Res=requests. Get (url=url, headers=self. Headers). The text
Return res
Def regex_f (self, regex, res) :
The pattern=re.com running (regex, re. I)
Lists=re. The.findall (pattern, res)
Return lists
Def parse_first (self, first_url) :
Res_first=self. Getres (first_url)
The links=self. Regex_f (self regex_first, res_first)
For a in the links:
Url_second=self. Second_url + a
Self. Parse_second (url_second)
Secondary page # parse function
Def parse_second (self, second_url) :
Res_second=self. Getres (second_url)
Title=self. Regex_f (self. Regex_title res_second)
Submissiontime=self. Regex_f (self. Regex_submissiontime res_second)
Final_decisiontime=self. Regex_f (self. Regex_decisiontime res_second)
Manuscript_submission=self. Regex_f (self. Regex_manuscript_submission res_second)
Submission_email=self. Regex_f (self. Regex_submission_email res_second)
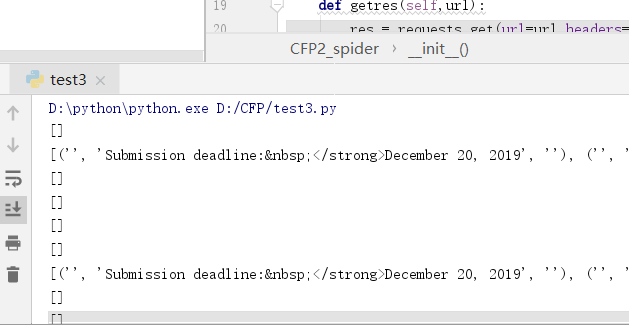
Print (the title)
Print (submissiontime)
Print (final_decisiontime)
Print (manuscript_submission)
Print (submission_email)
Self. Writecsv (title, submissiontime final_decisiontime, manuscript_submission, submission_email)
Def writecsv (self, title, submissiontime final_decisiontime, manuscript_submission, submission_email) :
With the open (' cfpmess3. CSV ', 'a', encoding="utf-8") as f:
Writer.=the CSV writer (f)
Writer. Writerow ([title, submissiontime final_decisiontime, manuscript_submission, submission_email])
F. lose ()
# entry function
Def run (self) :
Url=self. First_url
Self. Parse_first (url)
# main function
If __name__=="__main__ ':
Spiders=CFP2_spider ()
Spiders. The run ()
And I take the level of the crawler climb down directly assigned to the first child of the page requests the library to run, when get the result I wanted:
The import requests
The from fake_useragent import UserAgent
The import CSV
The import re
The from multiprocessing. Dummy import Pool
Linklist=[]
Title=[]
Submissiontime=[]
Manuscript_submission=[]
Submission_email=[]
Final_decisiontime=[]
Url_s='https://www.springer.com/journal/11263/updates/17198708'
The response=requests. Get (url_s). The text
Pattern1=re.com running (" & lt; H1 & gt; (. *?) Pattern2=re.com running (" & lt; p> . *? Submission deadline: & lt;/strong> (. *?) |
. *? (Submission deadline: [^ & lt;/strong>] . *?)
|Pattern3=re.com running (" & lt; [a zA - Z] & gt; (final. * decision:. *?) (final decision by. *?) " Re. I)
Pattern4=re.com running (" & lt; [a zA - Z] & gt; (final yoshinori miura. *? :. *?) Pattern5=re.com running (' ([a zA - z] + ://VISI [^ \ s] *? .com) ')
Title=re. The.findall (pattern1, response)
Submissiontime=re. The.findall (pattern2, response)
Final_decisiontime=re. The.findall (pattern3, response)
Manuscript_submission=re. The.findall (pattern4, response)
Submission_email=re. The.findall (pattern5, response)
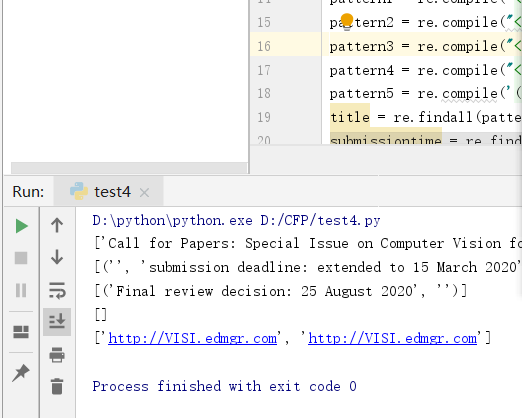
Print (the title)
Print (submissiontime)
Print (final_decisiontime)
Print (manuscript_submission)
Print (submission_email)
CodePudding user response:
Do the crawler for a long time, feeling, was it a successCodePudding user response:
