Def getStatusCode (url) :
Urllib3. Disable_warnings ()
R=requests. Get (url, verify=False)
Return r.s tatus_code
Driver. The get (" https://xxxxxxxxxx/")
Sleep (3)
Print (getStatusCode (driver. Current_url))
return to 403 status code, online to find the information added to the header, as follows:
Def getStatusCode (url) :
Urllib3. Disable_warnings ()
The header={' the user-agent ':' Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36 '}
R=requests. Get (url, verify=False, headers=headers)
Return r.s tatus_code
Driver. The get (" https://xxxxxxx/")
Sleep (3)
Print (getStatusCode (driver. Current_url))
status code of 200, consult everybody, this is why, I am here to get a lot of web page status code, always can't one by one for the header
CodePudding user response:
The header is certainly want to take, take a universal headerCodePudding user response:
403 who, which is an active refused, you have been discovered, headers are just a crawler, don't need a a copy, in addition to have a special verification, get requests are usually won't have a lot of restrictions, only need the user-agent, there are too many methods to build a headersCan give you a look at the background of a no headers crawler and the difference between the normal browser, just to see your identity, your guess I will not give you a
This is the crawler
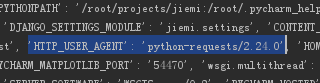
This is a normal browser

CodePudding user response:
If you climb baidu also have to Accept is added in the headerCodePudding user response:
Disguised as a regular user because you don't have the creeper crawled, it is best to give you want to crawl web pages headers to write complete, so as not to appear problem, because each page said need something different,