Want to crawl in HOME LINK network: lease way, the information such as housing types, but HOME LINK put this information in the span and li tags, result in itself is not a separate label, I don't know how to extract,
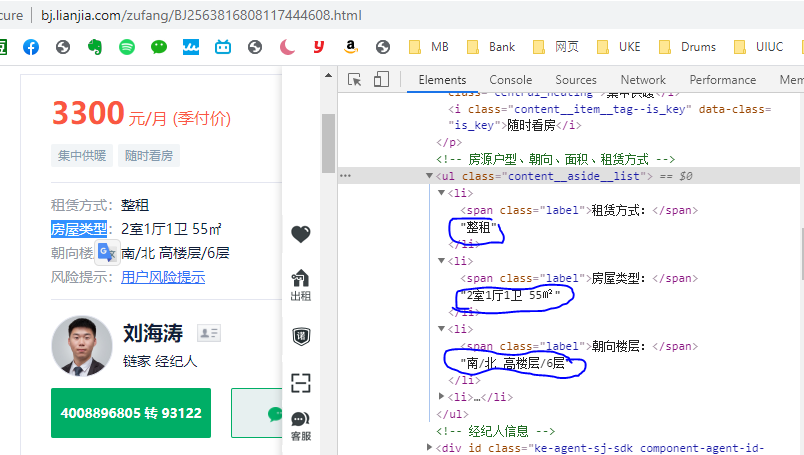
Now write the code as follows, and teach me ~ thank you! Just want to know if there is any way other than with sliced
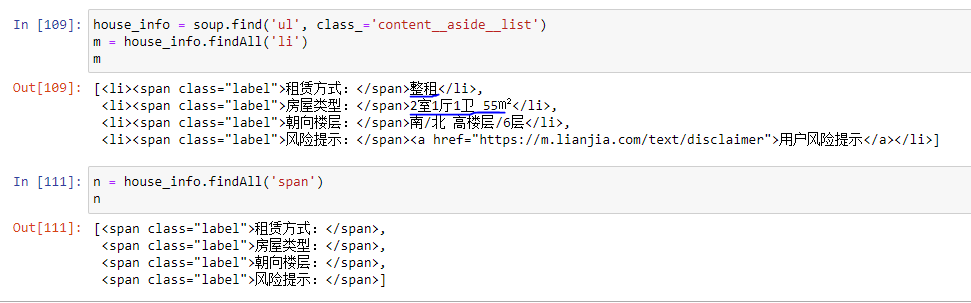
CodePudding user response:
The from bs4 import BeautifulSoup
Page_source="" "
"
Soup=BeautifulSoup (page_source, '. The HTML parser)
The item=soup. Find_all (' li ')
Print (item [0]. Contents [1])
CodePudding user response:
#! The/usr/bin/env python
# - * - coding: utf-8 - * -
The from bs4 import BeautifulSoup
The import requests
Url="https://m.lianjia.com/chuzu/bj/zufang/"
Headers={
"The user-agent: Mozilla/5.0 (Linux; The Android 6.0. The Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Mobile Safari/537.36 "
}
The response=requests. Get (url=url, headers=headers)
HTML=response. Content. decode (" utf8 ")
Soup=BeautifulSoup (HTML, "HTML parser")
For the tag in soup. Find_all (' div 'class_=' content__item ') :
Style=STR (tag. Find_all (class_='p', 'content__item__content')). \
The replace (' [& lt; p & gt; ', ' ') \
Replace (" ", ""). The replace (" \ n", ""). The replace (" & lt;/p> ] ", "")
Price=STR (tag. Find_all (class_='p', 'content__item__bottom')) [r]. 68-120 the replace (" ", "")
Page=tag. The find (" img "). The get () 'Alt'
Print (" {}, {}, {}/yuan each month ". The format (page, style, price))
CodePudding user response:
Is the code above, the following is running as a result, the hope can help you
CodePudding user response: