TXT=open (" a dream of red mansions. TXT ", "r", encoding="utf-8"), read ()
Words=jieba. Lcut (TXT)
Counts={}
For the word in words:
If len (word)==1:
The continue
The else:
Counts [word]=counts. Get (word, 0) + 1
The items=list (counts. The items ())
The items. Sort (key=lambda x: x [1], reverse=True)
For I in range (15) :
Word, count=items [I]
Print (" {0: & lt; 10} {1: & gt; 5} ". The format (word count))
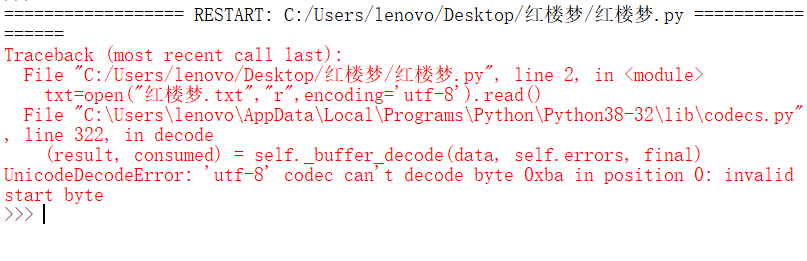
Ask what problems this is where ah?
CodePudding user response:
That means a dream of red mansions. TXT not utf-8 format, two kinds of solutions,What is 1, and check a dream of red mansions. TXT coding GBK (may be), according to the code modify encoding=parameter,
2, with UE or notepad + + is modified to utf8 encoding,
CodePudding user response:
To solve this problem, thank you,There's just one problem:
Print (" {0: & lt; 10} {1: & gt; 5} ". The format (word count))

Why Mrs King that line the format and is not the same as the other?
CodePudding user response:
Try to align good-looking, print (' {0} \ t {1} '. The format (a, b)) this formCodePudding user response:
The format {0: & lt; 10}: the number of characters followed by filling, can only be one character at a time, is not specified, the default is to use the Spaces filled,
The solution is:
Spaces filled in Chinese, Chinese space coding for CRH (12288)
print (" {0: {2} & lt; 10} {1: & lt; 5} ". The format (word count, CRH (12288)))